Layers du Datalake : une géologie de la data
Parce que j’aime la contradiction et que se tromper est souvent le début d’une meilleure idée, lisez aussi le meilleur contre-argument AI-generated à cet article.
La ligne de séparation entre un datalake et un dataswamp est souvent ténue. La fougue des premiers use cases et l’étourdissement provoqué par le sentiment d’une puissance de calcul infinie font rapidement perdre le sens des réalités : le datalake est en réalité un système de sédimentation de la donnée où il est difficile de corriger ce qui est enfoui par des années de pratiques souvent irréfléchies.
Ce constat, j’ai eu à le faire dès ma première expérience Big Data en 2012 lorsqu’on prototypait un grand datalake Hadoop pour un mastodonte bancaire français. À cette époque-là, nous avions en face de nous une bête dont l’écosystème était balbutiant et les bonnes pratiques Big Data quasi inexistantes (en tout cas pour mon niveau de maturité de l’époque). Il fallait penser autrement pour retomber sur des patterns architecturaux permettant plus ou moins de structurer notre travail.
Des années plus tard, je me rends compte à quel point il est encore difficile de trouver des pratiques formalisées claires et standardisées pour un datalake. Et à juste titre, le datalake monolithique, figé de 2010 a laissé place à des alternatives plus agiles où tout est virtualisé, où il est possible de se connecter à tout de partout, avec des formats ultra interopérables. Dans les pays où le Cloud a pris le relais de l’infrastructure classique (IaaS, mais surtout PaaS et SaaS, je pense notamment à databricks), la question de penser le datalake ne se pose plus, ou du moins pas aussi urgemment.
Au Maroc, le datalake reste un must-have pour tous ceux qui veulent profiter d’un écosystème robuste d’outils standardisés et bien supportés, bien qu’il soit souvent overkill pour nos usages et la quantité de nos données (sauf quelques grands acteurs, et encore). Il faut donc penser en amont une géologie du datalake pour structurer la donnée afin d’en faire une utilisation optimale.
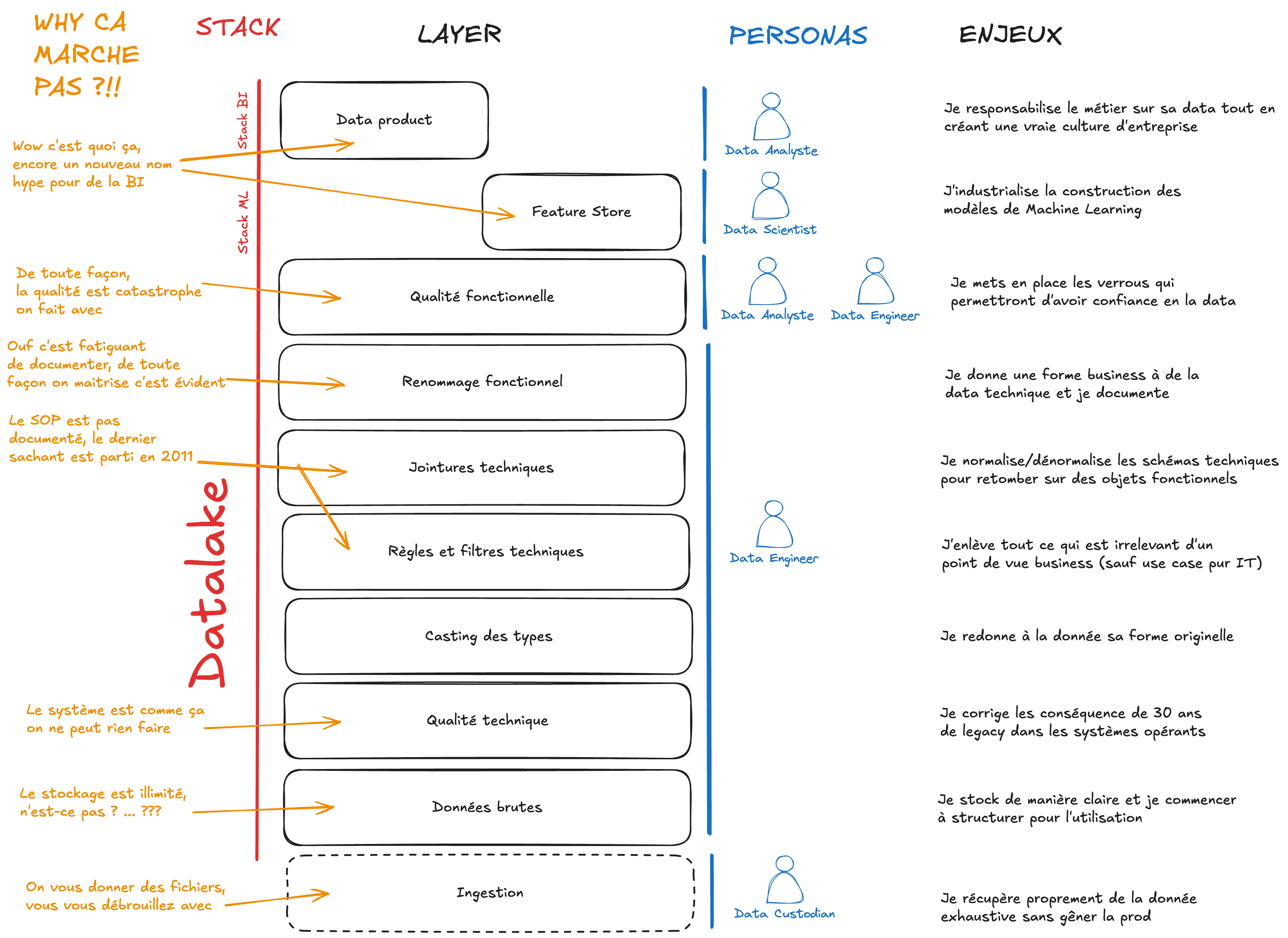
Voici donc une rapide synthèse de ce que j’ai vu, appris et compris sur ce sujet en particulier, illustrée par des snippets de code.
Géologie architecturale de la data
Attaquons le sujet par un peu de géologie schématique de la data. Un datalake est constitué des couches suivantes qui s’appliquent les unes au-dessus des autres :
Ingestion
- La couche ingestion : celle chargée d’ingérer la donnée brute issue des systèmes opérants vers les couches brutes du datalake. Cette couche est parfois temporaire et peut contenir des formats propriétaires non digestes. L’objectif ici est d’avoir uniquement un atterrissage technique pour des données arrivées d’autres horizons.
- En pratique : le chargement de fichiers la plupart du temps compressés, sous les formats CSV, JSON ou XML par ETL, API, JDBC etc. dans un répertoire de landing zone (ou potentiellement directement dans HDFS).
Illustration : Afin de récupérer les tables Oracle d’un système opérant monétique, je dois mettre en place un ensemble de scripts d’ingestion (par exemple Sqoop si la production m’autorise à accéder aux schémas monétique ou sur un réplica) qui vont tourner chaque soir pour récupérer les deltas. A défaut de Sqoop, la couche ingestion peut être constituée d’un ETL type Talend ou DataStage, ou encore de scripts d’extractions qui pour des raisons de sécurité sont gérés par le owner du système opérant lui-même (auquel cas, la couche ingestion échappe à la gouvernance Datalake). L’ingestion est sensitive car elle doit être réalisée avec les droits de production. Elle doit également être monitorée quotidiennement sinon en temps réel avec les bons mécanismes d’alerte en cas de soucis. De nombreux outils existent pour ce type de tâche (Apache NiFi, Airbyte, Debezium, Fivetran etc.) mais on a tendance à privilégier des solutions robustes et éprouvées en raison de leur stabilité et de leur support.
# Ce script récupère les transactions de la base oracle ORCLPDB1
# et les stocke dans HDFS dans target-dir
sqoop import \
--connect jdbc:oracle:thin:@//localhost:1521/ORCLPDB1 \
--username myuser \
--password mypassword \
--table TRANSACTIONS \
--target-dir /user/hadoop/raw_data/transactions \
--fields-terminated-by ',' \
--lines-terminated-by '\n' \
--null-string '\\N' \
--null-non-string '\\N' \
--num-mappers 4 \
--directData brutes
- La couche des data brutes : celle qui contient une donnée non modifiée sans transformation ni aucun enrichissement y compris technique. C’est néanmoins une couche lisible dans un format compatible datalake afin de permettre de l’archivage et une exploitation brute des données.
- En pratique : cela peut être des fichiers dans HDFS mais ce sont souvent des tables dans le Hive metastore qui représentent exactement la donnée reçue. La donnée a été décompressée et décodée, et est accessible pour des analyses très bas niveau, souvent de la piste d’audit ou la reconstitution d’évènements pour l’analyse d’une fraude passée
Illustration : Pour des besoins de web analytics, nous avons chargé les logs des serveurs web du front bancaire. Ces logs extrêmement massifs sont des fichiers compressés au format GZIP qui contiennent des milliards de lignes au format peu structuré avec des objets json imbriqués à l’intérieur. Les logs sont difficilement exploitables en l’état car les informations clés (montant, type de transaction, etc.) sont dispersées dans les objets imbriqués. Pour des besoins de lutte contre la fraude, nous avons chargé les logs dans des tables hive en utilisant quelques clés de recherche disponibles (date et numéro client). Ces logs sont considérées comme des données brutes car elles n’ont pas été retouchées à ce stade. Les objets jsons à l’intérieur des champs peuvent avoir été aplatis (ce qui simplifie la recherche) mais ce n’est pas systématiquement le cas.
-- Il s'agit de la création d'une table externe dans le metastore Hive
-- Cette table pointe sur le répertoire des fichiers CSV HDFS
CREATE EXTERNAL TABLE raw_transactions (
transaction_id STRING,
transaction_date STRING,
customer_id STRING,
amount STRING,
transaction_type STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hadoop/raw_data/transactions';
LOAD DATA INPATH '/user/hadoop/raw_data/transactions/*.csv'
INTO TABLE raw_transactions;Qualité technique
- La couche de qualité technique : celle qui permet de garantir que les données sont techniquement de bonne qualité, c’est-à-dire que les données sont bien lisibles, au bon format, complètes (au sens technique du terme) et correspondent bien à ce qui a été capté par le premier système (par exemple l’opérateur téléphonique du CRC ou le poste de travail de l’agence qui est face au client). La qualité technique est à distinguer de la qualité fonctionnelle qui est plus proche de la compréhension métier. La qualité technique est de la responsabilité des techniciens dataops (IT et équipes pur data). C’est à eux de s’assurer que l’information est bien captée, déplacée, retranscrite dans des bases suffisamment bien pensées et extraite de manière adéquate. Nous reviendrons sur la qualité fonctionnelle dans une couche plus haute.
- En pratique : Il faut vérifier que les données sont complètes, par exemple si une table transaction est récupérée, il faut que l’entièreté des transactions soit incluse dans le flux d’ingestion. Il faut également s’assurer que les dates sont au bon format (les formats peuvent changer entre les systèmes et au niveau de l’extraction pour ingestion dans le datalake). Des données non lisibles sont également de la responsabilité de l’équipe dataops, comme par exemple un séparateur de colonne qu’on retrouve à l’intérieur d’une chaîne de caractères sans caractère d’escape, un blob json mal formaté ou dont la syntaxe est inconsistante.
Illustration : Le sujet de la complétude est récurrent pour la qualité technique. Il nous arrive très souvent de demander une ingestion de data sur une période longue et recevoir un flux à trous, problème parfois difficile à quantifier. Pour éviter les problèmes de qualité technique, on instaure un certain nombre de contrôles techniques sur les données ingérées afin de réagir le plus tôt possible à d’éventuels problèmes. On vérifie que le nombre de lignes ingéré entre deux jours consécutifs ne varie pas de plus de 10%, on vérifie que les champs critiques comme les clés sont toujours remplis (numéro client par exemple), on vérifie que les champs de type identifiant n’ont pas de doublons (comme un identifiant transaction).
import com.amazon.deequ.VerificationSuite
import com.amazon.deequ.checks.{Check, CheckLevel}
import com.amazon.deequ.constraints.ConstraintStatus
// On vérifie un certain nombre de propriétés sur la table
// avec une syntaxe assez fonctionnelle et très lisible
val verificationResult = VerificationSuite()
.onData(df)
.addCheck(
Check(CheckLevel.Error, "Vérification de la complétude")
.hasCompleteness("transaction_id", _ >= 0.99)
.hasCompleteness("transaction_date", _ >= 0.99)
.hasCompleteness("customer_id", _ >= 0.99)
.hasCompleteness("amount", _ >= 0.99)
.hasCompleteness("transaction_type", _ >= 0.99)
)
.run()Casting
- La couche de casting : celle qui permet de donner à chaque champ brut (a priori sous format string) un type riche et adapté à sa nature, idéalement compatible Hadoop (attention aux doubles et flottants multiprécision) et qui reflète le format de stockage dans la source (dans une base Oracle par exemple)
- En pratique : un champ
dateest casté entimestamp, un champmontantest casté endoubleou encore un champblobqui reste sous format string car le casting doit se faire dans des couches hautes d’analyse (typiquement dans Spark car une librairie spécialisée doit être invoquée)
- En pratique : un champ
Illustration : Nous avons eu affaire aux schémas comptables dans des bases Oracle avec des précisions importantes notamment les Number(precision, scale) qui permettent de stocker des nombres avec une précision arbitraire. Le passage dans Hadoop nécessite un cast de la chaîne de caractères (ou des bytes si la donnée est sérialisée) en un type numérique compatible avec Hadoop. Autrement, nous devons faire attention au format de la date car celui-ci peut être modifié par la couche d’ingestion.
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
// Le cast est effectué ici avec spark grâce là encore
// à une syntaxe fonctionnelle lisible
val castedDF = df.select(
col("transaction_id").cast(StringType).as("transaction_id"),
to_timestamp(col("transaction_date"), "yyyy-MM-dd HH:mm:ss").as("transaction_date"),
col("customer_id").cast(LongType).as("customer_id"),
col("amount").cast(DoubleType).as("amount"),
col("transaction_type").cast(StringType).as("transaction_type")
)Règles et filtres techniques
- La couche des règles et filtres techniques : celle qui permet d’appliquer un certain nombre de règles techniques sur les données afin de garantir une utilisation optimale et interprétation métier correcte. Ces filtres constituent la première couche de modification sur la data. Les filtres techniques sont de la responsabilité des data engineers dataops (IT et équipes pur data) qui doivent garantir que tout ce qui n’a pas de valeur au sens analytique disparaisse à ce stade.
- En pratique : On enlève souvent des enregistrements morts, techniques, invalides ou de tests (ils se glissent parfois dans la production pour tester). On filtre des doublons techniques (comme l’identifiant d’un client qui aurait souscrit, puis résilié puis re-souscrit). On peut aussi être amenés à supprimer des colonnes inutiles (comme les numéros de cartes bancaires ou des dates techniques qui ne correspondent à aucune réalité métier), ou à créer de nouvelles colonnes sur la base de la combinaison technique d’autres colonnes.
Illustration : L’exemple typique de la règle technique est la reconstitution d’un montant à partir de plusieurs champs. Par exemple, si on dispose des champs montant HT, montant TVA et Flag Validité de la transaction, il est possible de reconstituer le montant TTC à partir des deux autres montants mais uniquement lorsque le flag est à Vrai, et mettre le montant à 0 dans les autres cas (car la transaction est invalide). Il n’y a que les gestionnaires du système opérant qui comprennent ce mécanisme de Flag (car une transaction peut être annulée a posteriori), c’est donc à eux de donner un sens métier au champ “montant” alors que celui-ci avait un sens technique. Un autre exemple plus prosaïque est de simplement supprimer des lignes de tests comme les fausses transactions effectuées sur le système pour tester régulièrement la disponibilité de celui-ci.
import org.apache.spark.sql.functions._
// Ici, on a un gros .filter() qui contient la clause WHERE
// des règles à implémenter
// Une meilleure pratique serait de regrouper les mini-règles
val filteredDF = df.filter(
col("transaction_id").isNotNull &&
col("customer_id").isNotNull &&
col("transaction_type") =!= "test" &&
col("amount").isNotNull &&
col("amount") > 0 &&
col("transaction_date").isNotNull &&
datediff(current_date(), col("transaction_date")) <= 365 &&
col("transaction_status") === "completed"
)Jointures techniques
- La couche de jointures techniques : celle qui permet de relier les données brutes entre elles selon les différentes clés techniques du schéma d’origine. L’objectif ici est de dénormaliser le modèle de donnée pour offrir une version plus facilement explorable et plus lisible : aucune clé technique ne doit apparaître au-dessus de cette couche. La dénormalisation augmente la redondance des données et peut être coûteuse en termes de stockage mais le trade-off dans Hadoop est la performance en lecture contre du disque. On ne dénormalise pas toutes les relations (sinon on aurait une méga “table” Hive de milliers de colonnes) mais uniquement celles qui sont nécessaires pour les analyses les plus fréquentes. La dénormalisation peut aussi être virtuelle (via des vues Hive ou des outils comme Dremio.
- En pratique : un schéma pour toutes les informations personnelles d’un client, un schéma pour toutes ses transactions financières sur le portail web, un autre schéma pour ses transactions en agence etc.
Illustration : Pour les besoins d’un acteur monétique, nous avons groupé les données en thématiques (client, carte, marchand, equipements, logistique des cartes et marketing). À chaque thématique, il fallait associer un certain nombre de visions consolidées facilement explorables. Pour la thématique client, il fallait une table qui regroupe toutes les informations personnelles du client (identification_client_tb), une table qui regroupe les informations de dernière activité du client (activité_client_tb) et une table qui regroupe toutes les interactions du client avec la société de services monétique (interaction_client_tb - email, sms, appels au CRC, manipulation GAB, visite en agence etc.). Pour la thématique carte, il fallait une table qui regroupe toutes les informations relatives à la carte et son propriétaire(identification_carte_tb), une table qui regroupe les informations relatives à la logistique de la carte (logistique_carte_tb - confection, customization, livraison, délais etc.) et une table qui regroupe les informations relatives à la gestion de la carte (gestion_carte_tb) avec notamment les événements tel un rejet, un blocage, une capture de carte etc. Une fois que l’ensemble des vues ont été créées, il est possible de créer des vues plus grandes en faisant des jointures métiers (sur un identifiant client ou un id de carte) afin de confectionner des dashboards. Le passage des jointures techniques à des jointures métiers (accompagnée d’une documentation exhaustive) facilite la prise en main autonome des métiers du travail de BI et permet aux équipes techniques de se focaliser sur les opérations à valeur ajoutée.
import org.apache.spark.sql.functions._
// Les jointures techniques permettent en général
// d'éliminer les identifiants techniques
val client360DF = clientDF
.join(activityDF, Seq("client_id"), "left")
.join(interactionDF, Seq("client_id"), "left")
.join(cardDF, Seq("client_id"), "left")
.select(
"client_id", "nom", "prenom", "date_naissance",
"adresse", "telephone", "email", "derniere_activite_date",
"nombre_transactions_30j", "montant_total_transactions_30j",
"derniere_interaction_date", "type_derniere_interaction",
"nombre_cartes_actives" "type_carte_principale"
)Renommage fonctionnel
- La couche de renommage fonctionnel : celle qui permet de donner une forme métier à la donnée. C’est une étape incroyablement importante car elle sacralise le passage de relais des techniciens vers les analystes et datascientists. Cette étape doit être accompagnée de dictionnaires de données qui seront la référence des nouvelles conventions de nommage.
- En pratique : Les équipes techniques et métiers se mettent d’accord sur les nouvelles conventions de nommage avec des définitions claires pour chaque champ important. Même si en général, il est possible d’inférer le sens à partir des nomenclatures techniques, il est fréquent que sur certains progiciels, les noms de champs soient obscurs, redondants ou parfois contre-intuitifs. D’autre part, les nouvelles informations construites à partir de filtres et de combinaisons de champs doivent être bien renseignées dans le dictionnaire avec mention des hypothèses de construction. Ce n’est que de cette manière que les équipes Data au global deviennent productives.
Illustration : Les client_id, id, customer_num etc. deviennent un numero_client unique dont la définition est partagée par tous et dont le sens est univoque. Les champs montant_a, mnt_x42 et amount_dev deviennent montant_autorise, montant_transaction et montant_devise par exemple. Un même champ date dans plusieurs sources doit être distingué en fonction de la spécificité métier : date_transaction, date_reception, date_effet, date_valeur etc.
Les 7 couches précédentes sont en général la responsabilité des data engineers dataops (IT et équipes pur data). Il est rare qu’un datascientist et a fortiori un data analyste viennent mettre les mains dans des données sans passer par une abstraction fonctionnelle. Les équipes data et métiers doivent travailler avec de la donnée structurée, pré-digérée avec les bons rapports de qualité et dictionnaires pour gagner du temps et produire le plus de valeur possible.
Quand je parle de sédimentation, je fais référence au fait que les couches précédentes suivent un cycle de vie plus lent que les couches suivantes. Les ingestions sont faites une fois et rarement retouchées sauf pour lorsqu’un nouveau système voit le jour dans le SI. Les couches de qualité et de jointures techniques sont conçues pour être durables et ne nécessiter qu’un effort ponctuel de maintenance. En ce sens, les données de ces couches sédimentent au fil du temps et l’effort des équipes data tend à se focaliser sur notamment les data products (qui suivent souvent la logique organisationnelle changeante de l’entreprise) et les feature stores (qui doivent être enrichis de nouvelles idées au fur et à mesure que de nouveaux algorithmes sont nécessaires).
val renamedDF = df
.withColumnRenamed("client_id", "numero_client")
.withColumnRenamed("montant_a", "montant_autorise")
.withColumnRenamed("mnt_x42", "montant_transaction")
.withColumnRenamed("amount_dev", "montant_devise")
.withColumnRenamed("date", "date_transaction")Qualité fonctionnelle
- La couche de qualité fonctionnelle : celle qui permet de vérifier que la donnée ne présente pas de problème fonctionnel dans le sens où elle représente correctement une réalité métier. C’est dans cette étape qu’on parle en général de data quality avec ses propriétés usuelles : complétude, unicité, cohérence, fraîcheur, exactitude etc.
- En pratique : On va vérifier que les champs critiques sont correctement remplis et les valeurs pas aberrantes. On mesure la fraîcheur de la donnée ainsi que la cohérence d’une même information dans plusieurs systèmes. Toutes ces propriétés sont mesurées et doivent être structurées dans des dashboards de qualité de la donnée qui seront utilisés pour comprendre les limites de l’utilisation de la donnée (certains use cases ne sont plus possibles avec de la mauvaise qualité de donnée) et pour entreprendre des chantiers d’assainissement et de correction.
Illustration : Pour mettre en place les verrous de qualité fonctionnelle sur une base client, nous devons nous assurer que tout client a un numéro d’identification unique, que les numéros de carte nationale sont complets et tous distincts. Il doit exister au moins un numéro de téléphone et une adresse par client. Les données de contact doivent avoir moins de 5 ans sinon elles doivent être marquées comme probablement obsolètes (à assainir par le chargé de clientèle). L’ensemble de ces indicateurs doit être suivi, historisé et calculé chaque semaine. Un rapport doit être communiqué aux lignes métiers opérationnelles concernées afin de lancer les campagnes d’assainissement nécessaires. Lorsqu’on utilise une information pour un rapport, on communique également son degré de qualité qui peut être interprété comme une mesure de la confiance en l’insight sous-jacent. Les données de très mauvaise qualité sont exclues des layers au-dessus.
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
// L'utilisation d'UDF permet de rendre modulaire
// la création de "mini tests unitaires de qualité"
def isValidDate(date: String): Boolean = {
try {
java.time.LocalDate.parse(date)
true
} catch {
case _: Exception => false
}
}
val isValidDateUDF = udf(isValidDate _)
val isValidCIN = udf((cin: String) => cin != null
&& cin.matches("^[A-Z]{2}\\d{6}$"))
val resultDF = df.select(
sum(when(isValidDateUDF(col("date_naissance")), 1)
.otherwise(0)).as("correct_birthdate_count"),
sum(when(isValidCIN(col("cin")), 1)
.otherwise(0)).as("correct_cin_count")
)Data Product
- La couche des data product : celle qui permet de donner à la data une forme exploitable pour toutes les personnes non techniques qui ont besoin de visualiser, manipuler et exporter de l’insight à partir du stock de données disponible. L’objectif final du data product est l’autonomisation des équipes métiers pour exploiter leurs données sans avoir à faire appel à l’équipe data, ce qui est réputé pour être un enjeu majeur dans les organisations data-driven. Le data product contient l’ensemble des informations nécessaires pour une utilisation adéquate de la donnée, notamment les dictionnaires de données, les filtres métiers utilisés, les agrégats calculés, les métriques de qualité de la donnée etc. mais également les accès aux outils permettant la consommation de la donnée sans avoir besoin des équipes techniques. C’est à partir des data product que le métier construit ses propres visualisations, réalise ses exports, et éventuellement pilote ses modèles de machine learning en grâce aux feature stores.
- En pratique : Sans être nécessairement dans un même outil, le data product peut être, pour par exemple le domaine client, l’ensemble des metadatas dans l’outil de data management pour les champs des tables liés au client (identification_client_tb, activite_client_tb etc.) On y ajoute des outils d’exploration comme Hue et Zeppelin, ainsi que des outils de visualisation comme PowerBI ou Tableau. Le data product étant sous la responsabilité du métier, ils peuvent gérer les accès aux données avec les droits adéquats dans une interface dédiée. Les informations sont recherchables dans un portail de data products. Chaque donnée a son propriétaire et ses métriques de qualité.
Illustration : Il faut imaginer ici que nous responsabilisons au maximum les équipes métier en décentralisant la gestion fonctionnelle de tous les aspects de la donnée. Sans parler de data management - ce serait un autre topic - nous pouvons créer un espace complet data product en utilisant des outils comme Datahub, Dremio, Zeppelin, Atlas et par exemple un ETL comme Talend
-- Ici nous avons uniquement la vue data du data product
-- sans les composantes data management et accès
CREATE OR REPLACE VIEW customer_360 AS
SELECT c.*, a.street_address, a.city, a.state, a.postal_code,
t.total_transactions, t.total_amount, t.last_transaction_date
FROM customer_info c
LEFT JOIN customer_address a ON c.customer_id = a.customer_id
LEFT JOIN (SELECT customer_id, COUNT(*) as total_transactions,
SUM(amount) as total_amount,
MAX(transaction_date) as last_transaction_date
FROM transactions
GROUP BY customer_id) t ON c.customer_id = t.customer_id;
CREATE OR REPLACE VIEW product_analytics AS
SELECT p.*, i.stock_quantity, s.total_sales, s.revenue
FROM products p
LEFT JOIN inventory i ON p.product_id = i.product_id
LEFT JOIN (SELECT product_id, COUNT(*) as total_sales, SUM(amount) as revenue
FROM sales
GROUP BY product_id) s ON p.product_id = s.product_id;
CREATE OR REPLACE VIEW sales_by_region AS
SELECT r.region_name,
COUNT(DISTINCT s.customer_id) as unique_customers,
COUNT(*) as total_sales,
SUM(s.amount) as total_revenue,
AVG(s.amount) as average_sale_amount
FROM sales s
JOIN customer_address ca ON s.customer_id = ca.customer_id
JOIN regions r ON ca.state = r.state
GROUP BY r.region_name; Source: Virtual Data Marts 101: The Benefits and How-To
Source: Virtual Data Marts 101: The Benefits and How-To
Feature Store
- La couche des feature store : celle qui permet de construire de manière automatique un grand nombre de variables numériques à partir des informations contenues dans les données sous tous les angles possibles et imaginables. Cette couche est dédiée à la préparation de la modélisation de Machine Learning et permet d’accélérer grandement la construction d’un nouveau score par exemple. Le feature store sert comme un cache hebdomadaire ou mensuel de toute l’intelligence (sous format numérique) de ce que contient le datalake.
- En pratique : Un feature store est une couche de donnée structurée historisée dans le datalake qui contient des variables calculées représentant tous les angles d’analyse de tous les phénomènes intéressants. Typiquement pour l’activité client, nous aurons des variables comme le nombre de transactions, le montant total des transactions, la date de la dernière transaction, le montant de la dernière transaction, le nombre de jours entre deux transactions, etc. Ainsi, la construction d’un score de fraude utilisera au maximum ces variables et pourra se faire en quelques jours au lieu de quelques mois. Un feature store doit contenir des informations historiques car la capacité à remonter dans le temps est cruciale pour backtester les modèles.
Illustration : Nous voulons construire un ensemble de scores de fraude autour des activités monétiques. Pour modéliser ce type de fraude, nous avons besoin de variables client, marchand et transaction avec un focus sur l’objet de la transaction. Pour simplifier le travail de modélisation, nous construisons un feature store pour chaque domaine : par exemple pour le feature store marchand, nous avons besoin de variables comme le code postal du marchand, la catégorie du marchand, le pays du marchand, etc. Nous avons également besoin du nombre de transaction moyen de ce marchand, du montant moyen des transactions ainsi que par exemple de la distribution des montants avec focus sur les montants importants et les montants parfaitement ronds. Ces variables ne serviront pas nécessairement à l’identification de la fraude mais sont un bon pas pour caractériser le marchand. Quelque part, le marchand est digitalisé à travers une empreinte numérique de tout ce qu’il représente pour notre entreprise. Le feature store est l’empreinte qui le caractérise. Les datascientists pourront puiser rapidement dans ce gisement de features pour itérer sur leurs modèles.
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
// La création des features est tout un art
val dateFeatures = transactions
.withColumn("is_weekend", when(col("day_of_week").isin(1, 7), 1).otherwise(0))
.withColumn("days_since_last_transaction", datediff(col("transaction_date"),
lag("transaction_date", 1).over(Window.partitionBy("customer_id").orderBy("transaction_date"))))
.withColumn("transactions_last_30_days", count("transaction_id")
.over(Window.partitionBy("customer_id")
.orderBy("transaction_date")
.rangeBetween(Days.days(-30).toMillis, 0)))
.withColumn("total_amount_last_90_days", sum("amount")
.over(Window.partitionBy("customer_id")
.orderBy("transaction_date")
.rangeBetween(Days.days(-90).toMillis, 0)))Grandes questions et principes dérivés
Quels grands principes faut-il retenir de la construction de ces couches géologiques sur le datalake ?
- Pourquoi recopier la data brute dans le datalake ?
- Rejouabilité : La couche data brute nous permet d’assurer un rejeu à souhait de l’ensemble des transformations et algorithmes ultérieurs à cette couche.
- Archivage : La possibilité de stocker de grandes quantités de données historiques ouvre la voie à des analyses profondes sur les tendances passées ainsi qu’à la mise en place d’algorithmes complexes de machine learning.
- Indépendance : Séparer la couche data brute système opérant de la couche data brute datalake permet de garantir une autonomie plus importante des équipes data vis-à-vis des équipes techniques ce qui accélère le time-to-market et décharge la DSI des extractions régulières et accès sauvages.
- Use cases techniques : La couche data brute peut aussi être vue comme un espace privilégié où la DSI peut analyser ses propres schémas de donnée en toute tranquilité sans perturber le système opérant et potentiellement développer des solutions pour répondre à ses enjeux (monitoring des systèmes, développement d’extractions techniques etc.).
- Pourquoi séparer la couche des données techniques de la couche des données fonctionnelles ?
- Découplage : En éliminant les champs techniques dans les couches supérieures, on a la garantie que les traitements dans ces couches sont robustes à tout changement de schéma en bas, notamment la mise à jour ou le remplacement d’un SOP (qui suivent, eux, leur lifecycle naturel d’obsolescence), robustes à la source de donnée de laquelle l’information est puisée (en l’absence de MDM - Master Data Management-, il est en général possible de se sourcer de plusieurs endroits pour récupérer une data générique) et robuste à toute décision technique de changer une règle d’agrégation ou de filtrage en bas (parce que par exemple la définition de client actif a changé ou parce que le montant de la transaction doit être calculé hors taxe dans les dashboards à partir de maintenant).
- Autonomie : L’utilisation de conventions de nommage fonctionnelles permet d’ouvrir la voie à une collaboration data plus inclusive des nouveaux venus et des personnes qui n’ont pas un background dans le business de l’entreprise. La séparation des couches est un prérequis technique pour simplifier cette autonomisation et entreprendre la marche vers un data management complet avec des data dictionnaires, du data lineage et des rapports de qualité de la donnée qui soient manipulables par des analystes data métier.
- Pourquoi sépare-t-on les différentes couches ?
- Effet spaghetti : Une structuration de la data qui suit ce process de raffinage linéaire demande un overhead de développement et d’architecture important, mais en rendant modulaire le traitement de la donnée, il est plus simple de s’y retrouver pour les développeurs. Le pari est qu’à moyen et long terme, cette simplification dans le traitement de la donnée réduira les problèmes, facilitera le debug et permettra de substituer une couche par une autre lorsque les techniques et librairies de traitement deviennent obsolescentes (ce qui arrive fréquemment)
- Collaboration : La séparation des couches permet également à des équipes de natures différentes (data custodian, data engineers, datascientists et analystes) de travailler sur une même codebase sans se marcher sur les pieds (à condition de bien maîtriser les outils de versionning). Appliquer sur le process de traitement de la data un schéma organisationnel similaire à celui de l’entreprise peut ne pas être efficient d’un point de vue technique mais facilitera la collaboration ce qui est souvent plus un pain point des entreprises que le fait de manquer de mémoire vive.
Conclusion
Penser le traitement de la donnée dans les datalake on-premise comme une stratification de couches géologiques est un framework de pensée qui peut être utile mais dont l’application n’a pas à être systématique. Dans des organisations où la compréhension de la data est évidente, la couche fonctionnelle s’efface car tout le monde sait de quoi on parle (et encore…). Lorsque les données sont toutes générées de manières automatiques, les couches de qualité fonctionnelle ne sont plus nécessaires car la data est exactement ce qu’elle est censée être par définition. Si les SOPs de l’entreprise sont bien pensés et structurés, les couches d’ingestion et de jointures techniques deviennent un simple passe-plat car toute la complexité de passer d’une donnée technique à une donnée métier a été préalablement digérée en amont.
Mais la vraie conclusion que j’ai envie d’écrire est que tout ça fera peut-être bientôt partie de l’histoire. Avec l’arrivée du cloud au Maroc (bien que timidement dans les grandes corporates), il faut de moins en moins coder les différentes couches géologiques et de plus en plus paramétrer des outils intégrés qui font tout ou partie du travail que j’ai décrit. C’est surtout valable pour les couches hautes de Business Intelligence, de Data product et de Feature store. Si votre SOP est dans le cloud (Salesforce par exemple), les couches inférieures deviennent également inutiles car le SOP vous donne accès à des dashboards et des APIs permettant de récupérer des vues fonctionnelles consolidées pour vous. Globalement, j’ai vu le monde de la data s’enrichir d’outils et de frameworks dans tous les sens mais ce modèle reste pour moi une façon nominale de penser traitement de la data (que ce soit sur un datalake ou dans une série de notebooks python).