Data Profiling ou le speed dating du datascientist
Tous les datascientists ont un rêve caché : celui de pouvoir parcourir, connaître et maîtriser toutes les données de leur organisation sur le bout des doigts. Le temps passé à faire de la data discovery, à chercher de nouvelles sources de données, et à comprendre toutes ses caractéristiques, est réputé être long, désagréable, peu gratifiant, et au final une source d’éloignement du coeur de métier : travailler et modeler l’algorithme pour extraire l’essence des données.
Nous explorons ici ce qu’il est possible de faire en phase de préparation amont d’un use case analytics pour raccourcir ce temps d’appropriation sur les données tabulaires, en illustrant les techniques de profiling.
Les bonnes pratiques de Data Management
Commençons par évacuer les pratiques essentielles qui accélèrent la prise en main de la donnée, mais qui ne sont pas du ressort du data profiling. Pour un datascientist qui n’a pas le luxe d’avoir 15 ans d’ancienneté dans une organisation complexe (l’exemple typique étant une banque du fait principalement de la diversité de ses données), son seul espoir est de trouver tout l’attirail classique laissé par les braves équipes de Data Management.
Chaque donnée est ainsi accompagnée d’un dictionnaire de donnée avec les trois familles d’information suivantes :
- Le sens fonctionnel de la donnée, c’est-à-dire le sens usuel donné par les métiers dans le cadre d’un ou plusieurs process
- Le lineage de la donnée, c’est-à-dire l’historique de l’ensemble des systèmes opérants produisant ou transformant la donnée en amont, ainsi que ceux qui la consomment en aval notamment les systèmes décisionnels
- La qualité de la donnée, c’est-à-dire un ensemble de métriques déjà préparées permettant de dire à quel point l’information représente de manière fiable la réalité qui est censée être mesurée
Dans les organisations les plus avancées, le datascientist peut avoir la chance de disposer de points de contacts (dits souvent référents data, comme les data custodians, data stewards et data owners) pour approfondir certaines caractéristiques de la donnée ainsi que des informations complémentaires sur la classification/sensibilité/conformité de la donnée vis-à-vis des politiques de l’organisation (cela peut se traduire par une interdiction d’utiliser une variable dans le cloud ou la permission d’injecter un type de variable spécifique dans un algorithme dans le cadre d’un process réglementé comme cela se fait dans l’assurance).
Les bonnes pratiques de Data Management permettent de construire une fiche d’identité complète qui facilite les premiers pas des nouveaux datascientists et la gestion usuelle de nouvelles données pour les plus anciens.
Aller encore plus loin avec le data profiling
Est-il possible d’extraire encore plus d’informations utiles de nos données de manière agnostique vis-à-vis de tout use case ? Partons d’un dataset tabulaire inspiré du monde bancaire constitué de l’ensemble de champs suivants :
Concernant les variables textuelles :
- Une variable CAT1 catégorielle de faible cardinalité : le segment d’un client parmi Seg1 Gold, Seg2 Silver et Seg3 Cuivre par exemple
- Une variable CAT2 catégorielle de forte cardinalité : la profession d’un client ou le prénom
- Une variable COM1 commentaire libre : typiquement un commentaire de conseiller clientèle
- Une variable ID1 de type identifiant sans pouvoir statistique a priori (cela peut ne pas être le cas si celui-ci n’est pas choisi aléatoirement): le numéro client
Concernant les variables numériques :
- Une variable NUM1 dont le range est normalement limité : par exemple l’âge du client
- Une variable NUM2 dont le range n’est pas a priori limité : par exemple les revenus déclarés
Attention, certaines variables numériques se comportent comme des variables catégorielles (par exemple identifiant de ville). Il faut bien veiller à les gérer de la sorte afin de ne pas mélanger le type de traitement de variables.
Concernant les variables de temps :
- Une variable DAT1 qui contient uniquement la date : typiquement la date de naissance
- Une variable DAT2 qui contient la date et l’heure : le timestamp de la dernière transaction avec la carte
Techniques de profiling
Traitement des valeurs manquantes
Commençons tout d’abord avec l’analyse des données manquantes. Pour cela, il faut comprendre qu’en fonction du type de donnée, une missing data peut revêtir des formes diverses.
La valeur générique que nous recherchons est en général le null qui peut correspondre au fait de ne rien avoir littéralement dans la cellule, ou bien avoir une variation orthographique du mot NULL (null, nil, na, nan, NaT, nul, undefined, None, NSNul, Nothing etc.) selon le langage de programmation, le type de base de données et le data type de la table. Parfois, la valeur manquante peut aussi être représentée par des espaces vides, des tabulations ou un ensemble de caractères spécifiques selon l’application qui a produit la donnée. Il est aussi possible de considérer que certains champs saisis par un opérateur correspondent à une intention de déclarer qu’il n’y a pas de valeur : par exemple N.A. (non applicable, non assigné) ou “-“ (un tiret pour dire “passe”)
Pour un champ numérique, le paragraphe précédent s’applique et on peut y ajouter certaines valeurs spécifiques comme le null zéro (un null transformé en zéro est fréquent par conversion non maîtrisée entre formats) et le null correspondant à des valeurs spécifiques int32.MaxValue etc. Le langage SPSS considère, par exemple, que 999 est le code par défaut pour définir une valeur manquante. C’est un paramétrage qui peut être modifié, l’important étant d’arriver à le distinguer de la distribution de la donnée.
Enfin concernant les champs de type date, là aussi on peut retrouver une valeur “vide” ou avec NULL mais également des dates spécifiques comme l’unix epoch 1970-01-01 ou des valeurs frontière comme 9999-12-31 23:59:59.9999999.
L’important est qu’il faut capter la facette métier d’une valeur manquante. Même si cette valeur n’est pas techniquement manquante (car de la data est présente dans la cellule), il faut toujours se poser la question si l’information renseignée traduit une réalité ou pas : l’exemple typique étant celle d’un opérateur qui par manque d’information remplira un champ téléphonique avec 0611111111 ou une date avec 2000-01-01 ou un champ numérique avec 0. Il est donc essentiel d’analyser le processus métier en amont dans toutes ses composantes y compris humaines.
Illustrons ce premier cas de profiling avec un dataset imaginaire en représentation colonne avec 3 observations
| Variable | Ligne 1 | Ligne 2 | Ligne 3 |
|---|---|---|---|
| CAT1 | Silver | Platinium | Gold |
| CAT2 | Dirigeant | Sans emploi | - |
| COM1 | Le client ne désire pas être sollicité par téléphone | \t | NULL |
| ID1 | 1 | 2 | 1 |
| NUM1 | 46 | 99 | 59 |
| NUM2 | 35.000 | -2.147.483.648 | 0 |
| DAT1 | 1970-01-01 | 9999-01-01 | |
| DAT2 | 2022-11-19 |
Après application du code suivant qui passe en revue l’ensemble des colonnes (par défaut chargées en StringType) pour en extraire les valeurs manquantes, nous obtenons notre premier rapport complet sur les valeurs manquantes :
private val defaultMissingSeq:Seq[String] = Seq("\t", "\\t", "9999-01-01",
"null", "-2147483648", "-", "—")
def getMissingStats(missingFeat:Seq[String]=defaultMissingSeq) = {
val cols = df.columns
cols.foldLeft(df) { case (df_arg, c) =>
df_arg.withColumn("missing_" + c, (col(c).isNull or
lower(col(c)).isin(missingFeat:_*)).cast(IntegerType))
}
.groupBy()
.avg(cols.map(c => "missing_"+c):_*)
.na.fill(0)
}| Variable | Pourcentage de valeur manquante |
|---|---|
| CAT1 | 0 |
| CAT2 | 0.333 |
| COM1 | 0.666 |
| ID1 | 0 |
| NUM1 | 0 |
| NUM2 | 0.333 |
| DAT1 | 0.666 |
| DAT2 | 0.666 |
Cette première vision permet d’éliminer d’emblée les variables inutilisables dans un algorithme ce qui peut faire gagner un temps précieux lors du cadrage d’un nouveau cas d’usage. Charge aux datascientists et dataengineers de renseigner, pour chaque type, la séquence de valeurs manquantes (celle-ci peut aussi être dans un fichier de configuration et pas hardcodée comme ici).
// TODO : à enrichir lors de la retrospective d'équipe
private val defaultMissingSeq:Seq[String] = Seq("\t", "\\t", "9999-01-01",
"null", "-2147483648", "-", "—")La famille MinMaxMean
Pour les variables numériques, le profiling classique off the shelf est simple et efficace. Prenons l’exemple de ce que fait la librairie Pandas de manipulation de données en python :
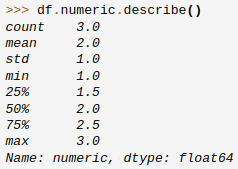
On obtient un résumé bâti sur les fonctions de synthèse :
- Le count : le nombre de valeurs non nulles (au sens de pandas) mais ici ce sera surtout une mesure du nombre d’enregistrements utilisables
- Les quartiles : 0% (minimum), 25%, 50%, 75% et 100% (maximum)
- La moyenne et l’écart type : descripteurs classiques de distribution statistique
Il est possible d’ajouter d’autres indicateurs comme la Kurtosis (mesure de la dispersion) ou la Skewness (mesure de l’asymétrie) mais il est peu probable que ces indicateurs complexes puissent avoir une lecture évidente sans un deep dive métier. Ils n’ont, par conséquent, pas vraiment de sens dans un cadre de profiling amont, mais plutôt au besoin dans le cadre d’ateliers spécifiques pendant le développement du use case.
Le code scala suivant permet de construire ce profiling numérique :
def getMinMaxMeanStats: DataFrame = {
val numericCols = df.schema.filter(
p => Toolkit.NUMERIC_TYPES.contains(p.dataType)).map(_.name)
val x = numericCols.map(c =>
Seq(min(c), max(c), avg(c), stddev(c), skewness(c), kurtosis(c)))
.reduce((a, b) => a ++ b)
df.select(numericCols.map(col):_*)
.groupBy()
.agg(count("*"), x:_*)
}Nous filtrons uniquement sur les colonnes de types numériques mais ce comportement peut être surchargé si nous disposons d’informations supplémentaires (lorsque le cast automatique “inferschema” est incorrect par exemple).
Le résultat est le suivant :
| Variable | Valeur de profiling |
|---|---|
| min(NUM1) | 12 |
| max(NUM1) | 99 |
| avg(NUM1) | 48.833333333333336 |
| stddev_samp(NUM1) | 29.267160208442952 |
| skewness(NUM1) | 0.6334665376928688 |
| kurtosis(NUM1) | 0.333 |
| Les autres variables… (NUM2 etc) | … |
On calcule également les percentiles avec les fonctions natives de spark :
def getPercentileStats: DataFrame = {
val numCols = df.schema.filter(p =>
Toolkit.NUMERIC_TYPES.contains(p.dataType)).map(_.name)
df.select(numCols.map(col): _*)
.groupBy()
.agg(count("*"),
numCols.map(c => percentile_approx(col(c), lit(0.25), lit(100))) ++
numCols.map(c => percentile_approx(col(c), lit(0.5), lit(100))) ++
numCols.map(c => percentile_approx(col(c), lit(0.75), lit(100))): _*)
.drop("count(1)")
}Avec le résultat suivant :
| Variable | Valeurs des percentiles |
|---|---|
| percentile_approx(NUM1, 0.25, 100) | 32 |
| percentile_approx(NUM1, 0.5, 100) | 45 |
| percentile_approx(NUM1, 0.75, 100) | 59 |
| Les autres variables… (NUM2 etc) | … |
Les valeurs fréquentes
Pour les variables catégorielles, mais également pour les autres types de variables dans certains cas, il peut aussi être intéressant d’avoir un tableau des valeurs les plus fréquentes. Cela permet parfois d’identifier très rapidement des distributions complètements biaisées (quasiment tous mes clients habitent à “Casablanca” auquel cas la variable n’a pratiquement plus de valeur statistique) ou atypiques (une portion signficative des transactions à l’international ont un montant qui est bizarrement exactement 19.999 dirhams, est-ce un contournement des systèmes de contrôle ou un type de fraude ?) voire synonymes de négligence (quasiment tous mes clients sont nés un 1er janvier, serait-ce une particularité de ma clientèle ou bien d’une agence qui n’a “pas le temps” de renseigner le jour et le mois de naissance ?)
Une manière simple de représenter les valeurs fréquentes est d’indiquer la valeur et son nombre d’occurence, pour, par exemple, les 5 valeurs les plus fréquentes. Pour les variables numériques ou temporelles, les valeurs fréquentes n’ont souvent aucun sens car la distribution est bien répartie.
On peut calculer les valeurs fréquentes en restant dans spark avec la petite gymnastique suivante :
def getFrequencyStats(nTop:Int): DataFrame = {
df.columns.map(col).map(
c => df.select(c).groupBy(c).count().orderBy(desc("count"))
.limit(nTop).withColumn("id", monotonically_increasing_id())
).reduce((a, b) => a.join(b, "id")).drop("id")
}Chaque ligne du résultat est un enregistrement avec son count :
| Variable | Enregistrement 1 | Enregistrement 2 | Enregistrement 3 |
|---|---|---|---|
| CAT1 | Gold | Silver | Platinium |
| count_CAT1 | 3 | 2 | 1 |
| CAT2 | Employe | - | Salarié |
| count_CAT2 | 2 | 1 | 1 |
| Les autres variables… (NUM2 etc) | … |
Traitement des identifiants
Les identifiants permettent de référer à une entité de manière simple et univoque à travers un nombre auquel se mélange tout type de caractères. L’exemple le plus simpliste est l’identifiant client auto-incrémenté (1, 2, 3…) qui représente une énumération de la base clientèle. L’adresse publique d’une wallet cryptographique est également un identifiant construit avec un hash algorithmique (ex : 10dcd3869986bfc129408a1fd1e0b4f5). Ce type de donnée ne contient en général pas d’information statistique sur la distribution (sauf si par exemple il est numérique auto-incrémenté, auquel cas c’est un proxy de l’âge de l’enregistrement, ou encore si l’identifiant est constitué de portions métier comme l’est souvent un numéro de compte avec la ville et le type de compte). Pour notre traitement générique de profiling, nous nous intéressons uniquement à l’indicateur suivant :
- Uniqueness : l’identifiant se répète-il dans le dataset et si oui à quelle fréquence et quel est le nombre d’enregistrement unique ?
Lorsque par exemple nous avons une base client dont chaque enregistrement est censé être unique à travers son identifiant, ces trois informations permettent d’avoir une idée de l’état de duplication des enregistrements. Des clients sont-ils dupliqués ? S’agit-il d’un seul client dupliqué des centaines de fois ou de tous les clients dupliqués une fois ?
def getDuplicateStats: DataFrame = {
val cols = df.columns
val nb = df.count()
df.groupBy()
.agg(count("*"), cols.map(c =>
round(countDistinct(c).divide(lit(nb)), 2).alias("uniq_pct_"+c)):_*)
.drop("count(1)")
}Il est alors simple de constater l’état de duplication de nos enregistrements. Ici, c’est surtout la duplication de la variable ID1 qui nous intéresse :
| Variable | Pourcentage d'unicité |
|---|---|
| CAT1 | 0.5 |
| CAT2 | 0.83 |
| COM1 | 0.83 |
| ID1 | 0.83 |
| Les autres variables… (NUM1 etc) | … |
L’analyse par valeur fréquente permet, en complément, d’obtenir ensuite les IDs qui seraient sur-représentés dans le dataset.
Profiling de date et de timestamp
Les dates sont des sources précieuses de données car elles servent souvent à contextualiser le reste des variables d’un dataset. Il est donc important d’avoir une idée précise de leur distribution en amont de la construction des variables. Les deux premières informations intéressantes sont le min et le max, à savoir la date de début et la date de fin de la variable, que nous pouvons obtenir à partir de la famille minMaxMean. Le nombre d’années présentes peut indiquer l’absence de représentation de certaines années. On peut aussi construire des indicateurs sur les durées de date manquante la plus longue et la plus courte.
Illustrons ce dernier indicateur avec le code scala suivant :
def getDateTimeStats: DataFrame = {
val W = Window //add here a custom partitioning (customer based for example)
val dateCols = df.schema.filter(p => Toolkit.DATETIME_TYPES.contains(p.dataType)).map(_.name)
val s_dateCols = dateCols.map(c=>c+"_datediff")
dateCols.foldLeft(df.select(dateCols.map(col):_*)) { case (df_arg, c) =>
df_arg.withColumn(c+"_shift1", lead(col(c), 1).over(W.orderBy(asc(c))))
.withColumn(c+"_datediff", datediff(col(c+"_shift1"), col(c)))
}
.select(dateCols.map(c=>c+"_datediff").map(col):_*)
.groupBy()
.agg(count("*"), s_dateCols.map(c => min(c)) ++ s_dateCols.map(c => max(c)):_*)
}Pour le résultat suivant représentant la plage temporelle (en nombre de jours) la plus petite (min) et plus grande (max) pour chacune des variables DAT1 et DAT2 :
| Variable | Durée en jours des plages (min/max) |
|---|---|
| min(DAT1_datediff) | 5783 |
| min(DAT2_datediff) | 27 |
| max(DAT1_datediff) | 2920812 |
| max(DAT2_datediff) | 13412 |
Pour les dates, nous pouvons également calculer des indicateurs de fréquence sur le mois de l’année et le jour de la semaine, mais ce faisant, nous commençons déjà à faire un peu de feature engineering :
def getMonthDowStats(nTop:Int): DataFrame = {
val dateCols = df.schema.filter(p =>
Toolkit.DATETIME_TYPES.contains(p.dataType)).map(_.name)
dateCols.foldLeft(df.select(dateCols.map(col): _*)) { case (df_arg, c) =>
df_arg.withColumn(c + "_month", month(col(c)))
.withColumn(c + "_dow", dayofweek(col(c)))
}
.addFreqCols(dateCols.map(c => c + "_month") ++
dateCols.map(c => c + "_dow"), nTop)
}| Variable | Enregistrement 1 | Enregistrement 2 | Enregistrement 3 |
|---|---|---|---|
| DAT1_month | null | 1 | 3 |
| count_DAT1_month | 2 | 2 | 1 |
| DAT1_day_of_week | null | 6 | 5 |
| count_DAT1_day_of_week | 2 | 1 | 1 |
| Les autres variables… (DAT2 etc) | … |
Gestion des données de type texte long
Les commentaires, libellés, motifs clients et descriptions sont souvent très riches et concentrés en information. Ce type de variable nécessite des algorithmes de Natural Langage Processing (les algorithmes GPT étant leur évolution ultime à ce stade) adaptés afin d’en tirer toute la valeur possible. En amont, il est possible de profiter de cette richesse pour tirer quelques informations intéressantes :
- Le mot le plus fréquent de tous les enregistrements (modulo stop words par exemple)
- La longueur moyenne du champ
- Un ou plusieurs mots qui représentent le sens global du champ selon un algorithme de Latent Discrimination Analysis
L’idée est de faire un feature engineering préliminaire sur la variable texte indifféremment du use case de manière à le simplifier. Ce type de traitement va au-delà du profiling certes, mais n’en est pas moins indépendant du use case.
Cherchons simplement le mot le plus fréquent et faisons-en une analyse fréquentielle :
def getTextWordStats(cols: Seq[String], nTop:Int): DataFrame = {
cols.foldLeft(df.select(cols.map(col):_*)) { case (df_arg, c) =>
df_arg.withColumn(c + "_spl", explode(split(col(c), " ")))
}
.addFreqCols(cols.map(c => c + "_spl"), nTop)
}Le résultat permet d’avoir une première idée des mots qui reviennent souvent, et par la suite d’itérer pour enlever les stop words ou rajouter un filtre sur la longueur minimale du mot.
| Variable | Mot top 1 / nb occurence | Mot top 2 / nb occurence | Mot top 3 / nb occurence | Mot top 4 / nb occurence | Mot top 5 / nb occurence |
|---|---|---|---|---|---|
| COM1 | par | ne | Le | CONTACTER | sollicité |
| COM1_count | 1 | 1 | 1 | 1 | 1 |
Ouverture sur du profiling multivarié
La construction de variables de profiling précédentes s’est faite de manière univariée, c’est-à-dire en partant du principe qu’il n’y avait pas de dépendance entre les variables, ce qui est bien entendu faux. Il est possible de construire un profiling du dataset en amont sur la base du lien entre plusieurs variables.
Par exemple :
- Construire les variables de profiling MinMaxMean sur le top 3 des catégories les plus représentées dans les variables catégorielles
- Construire les variables de profiling de texte en distinguant les années des variables de date, pour les 5 années les plus récentes
- Construire les variables de profiling d’identifiant en supprimant les enregistrements qui ont au moins une valeur manquante (l’enregistrement est alors jugé inutilisable)
D’autres idées peuvent être pertinentes dans un contexte métier particulier et il est du ressort des datascientists et data engineers de chercher en amont le meilleur set de variables de profiling pour gagner du temps en avance de phase sur tous les use cases data qui suivent. Rien n’empêche les équipes Data de prendre un peu de temps sur chaque table pour établir les règles de profiling les plus adaptées à une famille de use case par exemple.
De plus, ces règles de profiling créent également des synergies avec le monitoring de la qualité de la donnée puisqu’en installant des sondes automatisées sur certaines valeurs de profiling, il est possible de détecter des évènements de dégradation du contenu du dataset.
Conclusion
Le profiling nous a permis d’accéder, en quelques étapes simples, à une vision synthétique de l’information contenue dans le dataset originel. Avec seulement quelques lignes de code génériques, il est possible d’automatiser la construction de ce type de profiling et de le mettre à disposition des datascientists et éventuellement des métiers qui peuvent s’en servir pour augmenter leur niveau de compréhension de la data et remonter des problèmes sur la donnée. De par mon expérience, je n’ai pas eu l’occasion de voir une telle approche mise en oeuvre sauf lorsqu’elle venait nativement (par exemple avec Apache Hue ou Pandas), et seulement de manière basique.
Il n’empêche que l’intuition nous dicte qu’une organisation mature qui pense la valorisation de la data à long terme devrait investir dans ce type de profiling car il est à même d’augmenter la productivité de use case des équipes Data.
Code
Tout le code utilisé est disponible sur le repository github suivant : https://github.com/AshtonIzmev/spark-data-profiling-toolkit
Note importante
Cet article est garanti 100% humain, GPT-free :)