Le Data Office, au coeur de la valorisation de la donnée

Cette présentation a été réalisée à distance dans le cadre de la sixième conférence du Capital Humain Groupe / Recrutement et Relations Universitaires à Attijariwafa bank et qui a regroupé un public divers allant des étudiants aux professionnels de la data. Elle a pour but de présenter une vision décalée de la façon dont la thématique de la donnée doit être traitée dans un grand groupe. Cette vision est bâtie autour du rôle d’un Data Office vis à vis des métiers et des informaticiens.
J’adopte un style plutôt oral dans cet article puisque c’est globalement une transcription écrite des idées de mon talk.

Mais avant de poser les bases de notre réflexion, il me paraît nécessaire d’aller à la chasse d’un certain nombre de mythes qui ont la peau dure. Ces mythes déforment la perception du grand public et des nouveaux entrants dans le monde de la data sur la manière dont la valeur est générée. Quels sont ces mythes ?

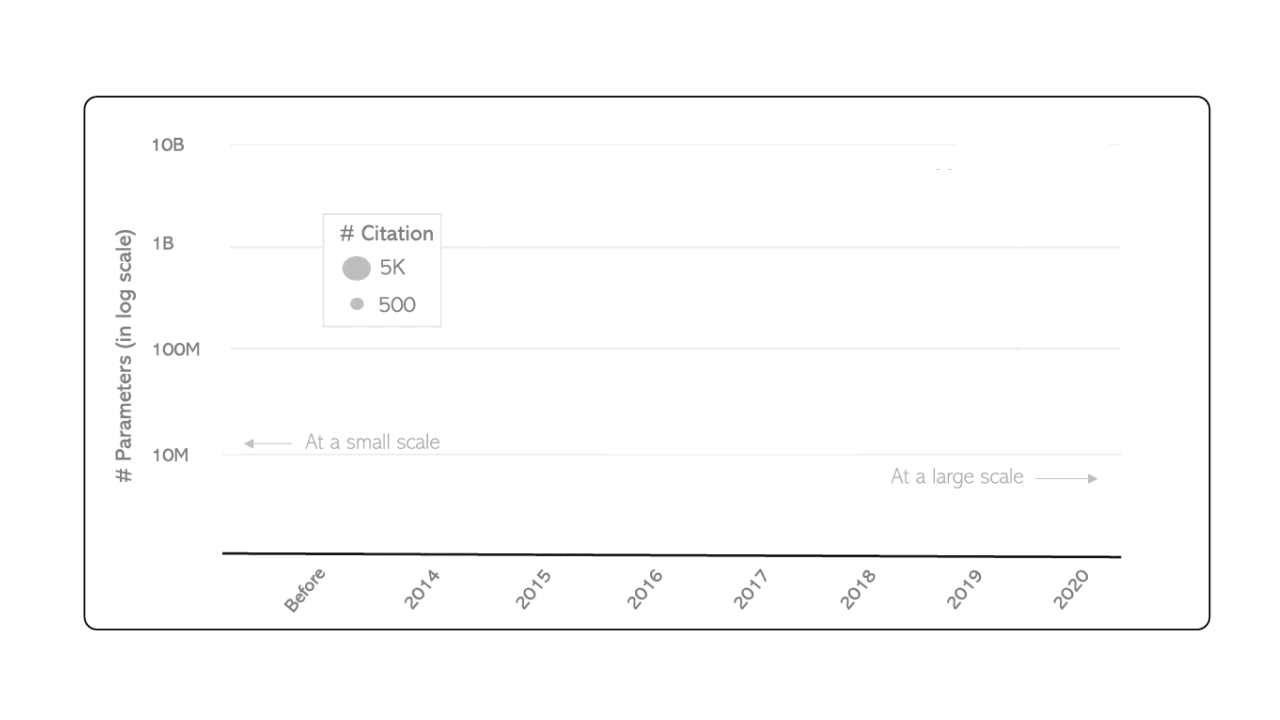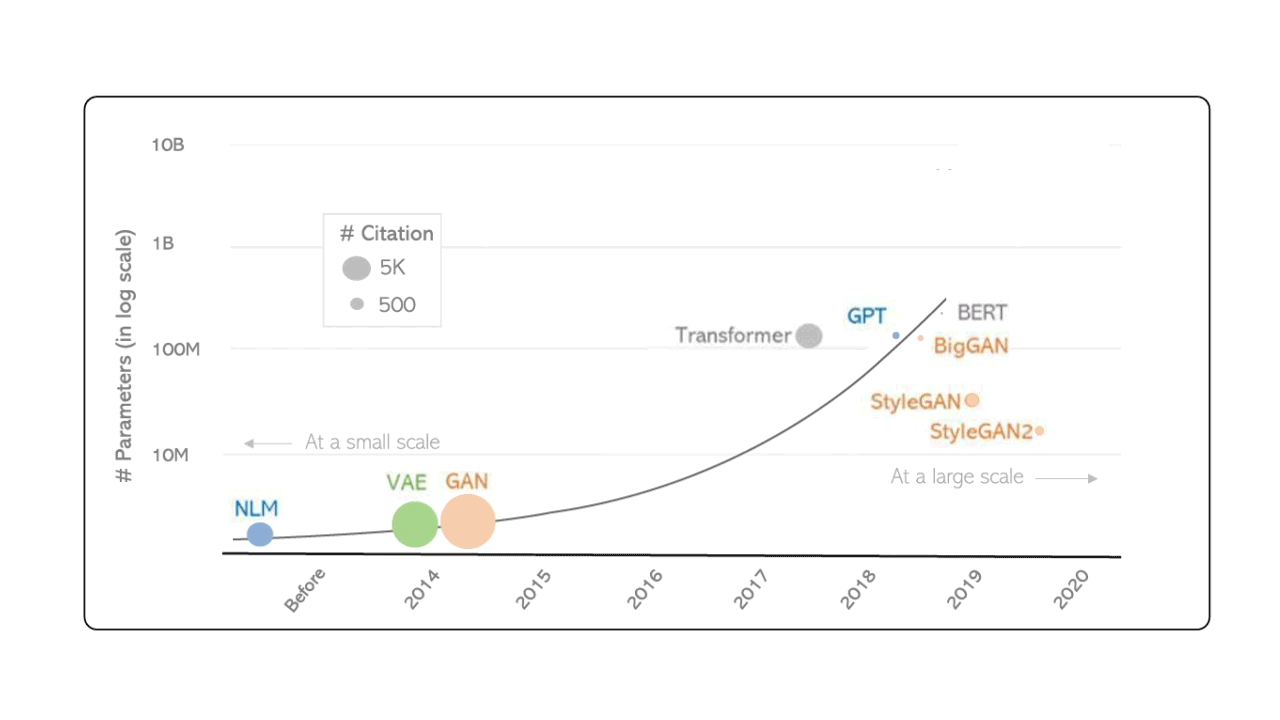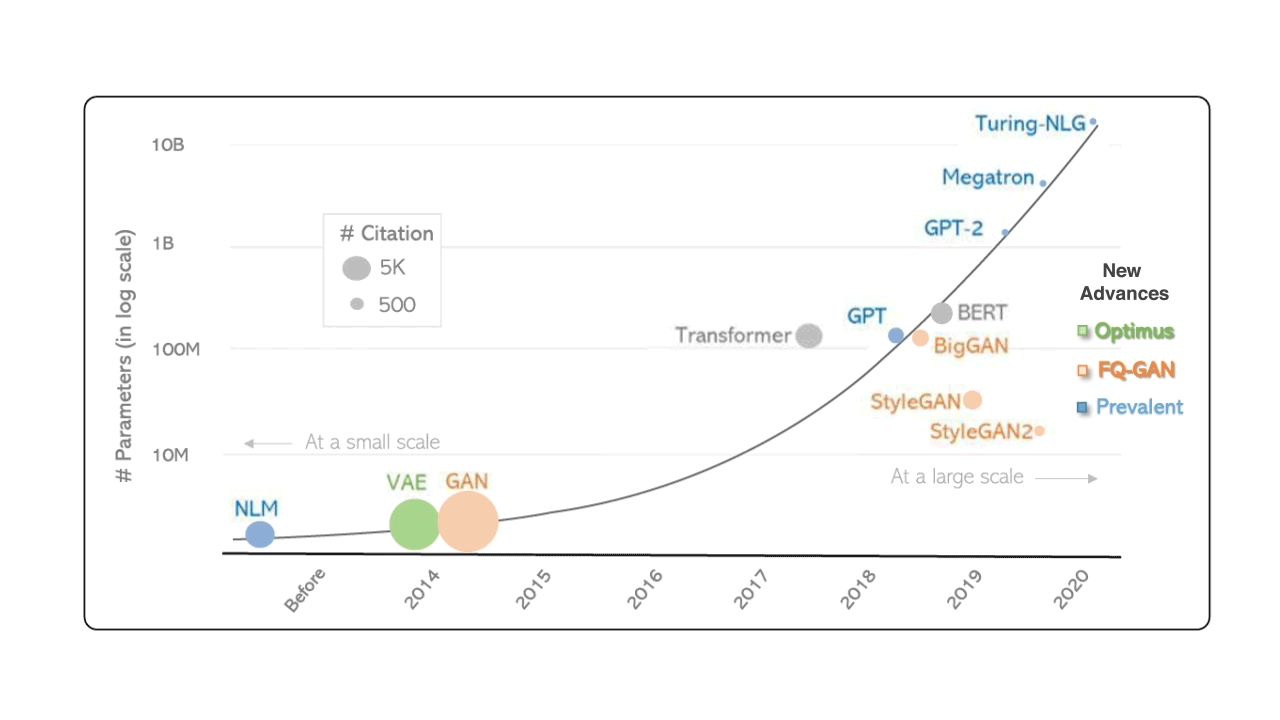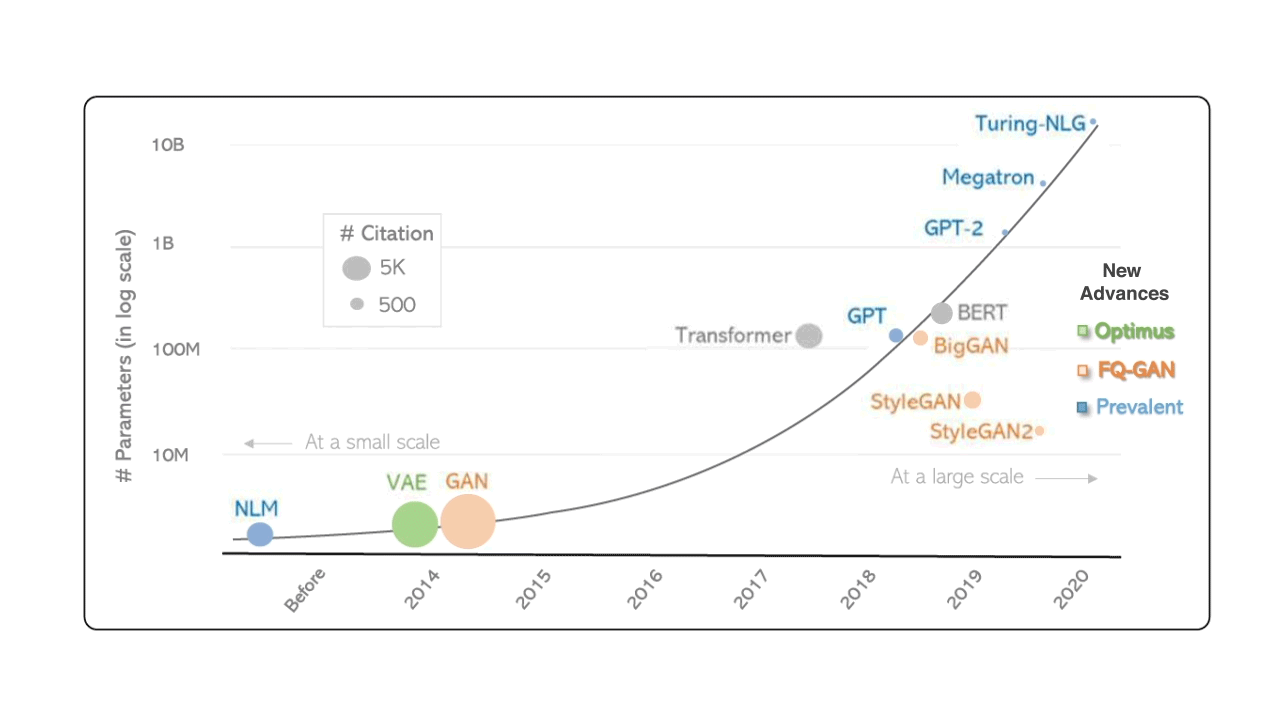
Le premier mythe est la croyance qu’une intelligence artificielle surpuissante est sur le point de prend le contrôle de l’ensemble de notre monde. Cette forme de hype est portée par des courants futuristes qui veulent voir ces prophéties se réaliser tout du moins dans l’inconscient collectif. Cette idée de disruption imminente est souvent basée sur l’évolution non linéaire de métriques comme par exemple celles permettant de mesurer le nombre de paramètres des modèles génératifs :
Le deuxieme mythe que j’aimerais déconstruire c’est Data is the new Oil. L’image était frappante il y a 15 ans car cela signifiait qu’il fallait se précipiter sur la data comme on se précipite sur un champs pétrolier. L’analogie est pertinente d’un point de vue technique pour les data engineers surtout, à travers la notion de raffinage et d’extraction d’information. Mais quelque part, je trouve cette définition assez restrictive car elle ne montre pas l’étendue du problème.
Et puis le troisième point, Big Data is the solution. A tout problème il existe une solution et cette solution passe forcément par le Big Data. C’est le mythe entretenu par la montée en puissance phénoménale des GAFA, et effectivement la recette fonctionne pour eux, mais le Big Data est-il vraiment la solution dans une banque, une assurance ou encore dans une entreprise de grande distribution ?

Tel que je le vois, le concept d’intelligence artificielle est plutôt oxymorique. Sans rentrer dans des débats philosophiques indécidables, il s’agit d’un raccourci de langage qui considère que l’intelligence n’est qu’une forme de computation puissante reproduisible par un algorithme.
On mélange ainsi deux notions très puissantes :
- L’artifice d’un côté, c’est le produit de la capacité humaine à décrire, reconstruire puis automatiser un phénomène. La brique de base de la technologie.
- L’intelligence d’un autre côté, c’est la capacité à structurer les idées, à se projeter, à penser, à s’adapter… C’est précisément ce qui produit l’artifice à travers l’inventivité et la créativité des chercheurs.
Parler d’intelligence artificielle me paraît être une combinaison malheureuse qui masque une complexité non résolue d’un point de vue technologique jusqu’à aujourd’hui.
On retrouvera cette notion énormément dans les articles à sensation, dans les blogs ainsi que chez les vendeurs de solutions qui répèteront “il faut faire de l’intelligence artificielle car c’est le futur”. Quand on creuse un petit peu, quand on est un peu curieux, quand on est un datascientist avec les yeux un peu ouvert, on se rend rapidement compte que ce qu’on entend aujourd’hui par intelligence artificielle, ce sont principalement des statistiques masquées par des couches de librairies techniques renforcées d’une bonne méthodologie et d’un peu de créativité.
Il y a des statistiques qu’on comprend bien, les statistiques classiques. Et il y a des statistiques qu’on comprends un peu moins bien. Ces statistiques-là sont une grande marmite qu’on va touiller sans relâche, typiquement les réseaux neuronaux qui forment l’ossature de ce qu’on appelle le deep learning. Et in fine en brut-forçant, cette soupe nous donnerait de l’intelligence artificielle ?

Derrière les rideaux, les gens s’imaginent qu’il y a quelque chose qui réfléchit, qui pense, qui anticipe et structure, alors qu’en fait nous avons fondamentalement à faire à surtout beaucoup d’algèbre linéaire.
Associer les mots intelligence et artificielle sans prendre des précautions d’usage peut revêtir la forme d’un charlatanisme si cette expression est utilisée pour impressionner ou vendre.
Au risque de m’avancer hâtivement, j’ouvre le débat
Ces gens viendront vous dire “vous avez un problème et moi j’ai la solution : c’est tel algorithme qui résoudra votre problème”. Pourtant, l’algorithme n’est pas le vrai pain point mais l’organisation data derrière.
- Avez-vous vérifié la qualité de la donnée ?
- Avez-vous une bonne compréhension du problème ?
- Maîtrisez-vous le sens, l’origine et les règles métiers de la donnée ?
A la rigueur, si nous voulons parler d’intelligence artificielle, il existe des initiatives comme celles de Deep Mind ou d’OpenAI qui vont dans le sens de résoudre de réels problèmes nécessitant de nouveaux algorithmes puissants. Alphago, alphastar, GPT2, GPT3 pour ne citer qu’eux. Et dans ces cas-ci, on peut peut-être parler d’intelligence artificielle vu la complexité des problèmes auxquels ils font face bien que ces problèmes soient très spécialisés. Plus généralement, j’essaye de bannir de mon vocabulaire cette notion d’intelligence artificielle et préfère parler de Machine Learning.

Le deuxième point crucial, c’est data is the new oil. La métaphore du raffinage est intéressante car elle permet de comprendre précisément ce qu’il se passe sous le capot. La data est une forme de matière brute qu’on va transformer par une suite d’étapes linéaires et c’est au fur et à mesure de ce raffinage qu’on va extraire des pépites d’information, de savoir ou de valeur. C’est illustré par la fameuse pyramide donnée / information / savoir / sagesse. Mais dans une organisation complexe et structurée comme une banque, il me semble que ce n’est pas la bonne façon de voir les choses.
La donnée est fondamentalement une forme d’actif immobilier. On peut voir les gisements de données comme des immeubles délabrés dont il faut s’occuper. Il faut refaire les façades, nettoyer les pièces, décorer l’intérieur pour pouvoir valoriser les biens en louant des chambres ou accueillir des événements sur la terrasse. Le paradigme crucial ici consiste à renverser l’idée de data comme étant une matière première brute en entrée d’un process de raffinage. Et la penser plutôt la data comme étant un actif stratégique au coeur de la valorisation. La valeur ne vient pas du fait que la data is the new oil mais de la capacité d’une organisation à se structurer pour raffiner efficacement la data.
La valeur n’est pas dans le bien mais dans la capacité à bien le gérer.
Pour rester sur la métaphore de la matière première, on dira que la valeur ajoutée réside dans le process de transformation.

Le troisième grand mythe, c’est celui du Big Data. On a parfois l’impression d’entendre les médias répéter que c’est une sorte de solution magique ou promesse mirifique à de nombreux défis de notre société. De mon expérience de consultant, on a rarement besoin de Big Data. Nos problématiques ne résident pas dans l’aspect “Big” de la data car :
- d’une part, on ne rencontre que rarement des volumétries nécessitant de sortir l’artillerie lourde algorithmique
- d’autre part, les solutions techniques demandent à être maitrisées alors qu’on a souvent des alternatives plus simples en terme d’outil
Le tableau n’est néanmoins pas totalement noir : Le Big Data permet des traitements plus efficients et un scaling hardware horizontal. L’écosystème Big Data s’est standardisé autour de la solution Hadoop ce qui simplifie l’identification des compétences en diminuant la fragmentations des technologies nécessaires pour traiter la donnée (bien que cet écosystème soit vaste). Pour les petites organisations, partir sur des solutions Big Data c’est aussi profiter d’outils existants probablement surdimensionnés par rapport au besoin mais déjà packagés sans prise de tête.
Notons que le rachat récent de Hortonworks par Cloudera est à mon sens en train de mettre en péril ce qui a fait la force de l’écosystème Hadoop ces 10 dernières années.
Pour revenir à la réalité, il s’agit surtout de résoudre des problèmes de data plutôt que de Big Data.

L’idée de cette présentation, c’est d’aboutir sur une vision réaliste du rôle d’un data office : comment se comporter avec la data en tant qu’organisation, en tant que datascientists, en tant que manager de la data ?

Il y a beaucoup de vendeurs de magie noire. Des commerciaux qui ont surfé sur une forme de superficialité, de méconnaissance ou d’incompréhension de fond de la part des managers. Tous les problèmes deviennent des clous lorsqu’on dispose d’un marteau. Ces vendeurs diront qu’on va générer tel pourcentage de valeur sans avoir au préalable déminé les sujets de qualité et de disponibilité de donnée, ni toute la stack de valorisation de la donnée. Et puis ces mêmes vendeurs promettront le tout automatique : pas d’être humain, il faut juste cliquer sur un bouton tous les mois et l’intelligence artificielle tourne toute seule.
Pour moi, il n’y a pas de valeur magique, car celle-ci se construit à travers une approche itérative, pensée avec les utilisateurs finaux. Le plus compliqué dans notre métier, c’est de garder une approche la plus agile possible sans perdre en capacité de planification en essayant de résoudre les problèmes au fur et à mesure. Pour l’automatisation, c’est la même bataille : la promesse est de se passer d’intervention humaine puis on se rend compte un peu plus tard qu’il y a 10% des cas où il faudrait contrôler une décision ou corriger un process car, voyez-vous, ce serait dommage de provoquer une erreur grave. Je m’insurge contre ces vendeurs. Et je porterai le message à nos managers, mais je m’adresse surtout à vous aujourd’hui si vous vous intéressez au sujet pour dire “there is no free lunch”. On ne peut pas manger gratuitement. Si on vous promet des merveilles, méfiez-vous car il y a toujours des coûts cachés quelque part et vous avez la responsabilité de les chercher.

Maintenant, on va casser ces mythes, et essayer de rétablir une forme de vérité. J’avancerai là encore des idées quelque peu fortes, mais dans ce type de débat autour de l’IA, il faut avoir des convictions tranchées quitte à faire parfois l’avocat du diable pour défendre ses convictions. Et ainsi arriver in fine à une vérité intermédiaire que se forgera le lecteur.

La recette miracle est composée de rigueur, de documentation, de discipline, de documentation, du bon sens, de l’energie et de la motivation. Qu’on soit dans l’IT ou dans la datascience, qu’on soit un manager ou un technicien, il n’y a fondamentalement pas de secret : vous faites votre travail correctement et vous avez des résultats. Même sans datascience avancée, avec juste quelques modestes règles métiers et vous produisez naturellement de la valeur. Pas de fancy algorithme, quelques règles whitebox, bien comprises, bien conçues, bien pensées avec une feedback loop continue et planifiée. Les moins expérimentés ont tendance à oublier que ces softs skills sont la clé d’un travail bien fait, bien avant la maîtrise technique des boîtes à outils statistiques.
Notre problème fondamentalement c’est comment transformer le déchet/mythe/bricolage en un actif/une réalité/un travail professionnel.
-
Le déchet c’est quand on considère que la donnée n’est qu’un byproduct de l’activité informatique. On entendra “ce sont juste des logs”, “de toute façon la donnée est de mauvaise qualité”, “les chargés de clientèle ne saisissent pas correctement”, “la donnée n’est pas fiable”. Si la donnée est vue comme un déchet, alors elle le restera et on n’ira jamais se dire que “ces déchets” sont valorisables, qu’il faut raffiner, réutiliser, transformer les déchets en actifs. Notre préconception parfois négative détermine l’entrain et l’envie que nous déployons à ouvrir des chantiers de valorisation.
-
Le passage du mythe à la réalité consiste à oublier la vision fantasmagorique que j’ai présenté plus haut pour aboutir à une vision concrète et pragmatique basée sur une approche itérative, humble et à l’écoute de ce qui nous entoure.
-
Passer du bricolage au professionnalisme est tout un art qu’on n’apprend généralement pas dans nos études. La différence entre un challenge Kaggle fait à la maison et une vraie problématique bancaire de datascience est abyssale en terme de type d’exigence. Je vois parfois passer du code sur linkedin et je me dit c’est vraiment below standards. Comment peut-on être publier un tel travail et l’afficher comme une fierté. Ou est la méthodologie, la rigueur ? Cette dernière n’est pas seulement mathématique et statistique, mais également dans l’approche, par exemple dans la recherche du sur-apprentissage, dans l’exploration et visualisation de la donnée, dans les effets de bords avec la gestion des outliers. Il existe une vraie profession de la datascience et vous ne la trouverez pas dans un mooc, ni sur internet, mais seulement en vous confrontant au terrain et à la réalité du end-user. C’est-à-dire en appliquant vos modèles sur des tailles d’échantillon et échelles de temps suffisamment longues pour faire émerger la nécessité d’éprouver et maintenir vos modèles.

Alors comment transformer le déchet, le bricolage et le mythe ? Là encore on se trompe de question :
Il faudrait en réalité se demander comment nous transformer nous, transformer nos organisations, car la data est au carrefour organisationnel de la banque. J’aime bien voir la data comme le sang qui alimente les organes vitaux. Réinventer la façon de travailler la donnée passe nécessairement par une réinvention organisationnelle, les impacts techniques étant presque relégués à des sujets structurants mais gérables modulo suffisamment de moyens et une vision architecturale claire. Les outils sont aujourd’hui gratuits et avec un pc high end et quelques disques SSD, je pourrais faire 70% de la datascience de la banque en utilisant intelligemment les bonnes librairies. Et ça, on ne le sait pas assez.
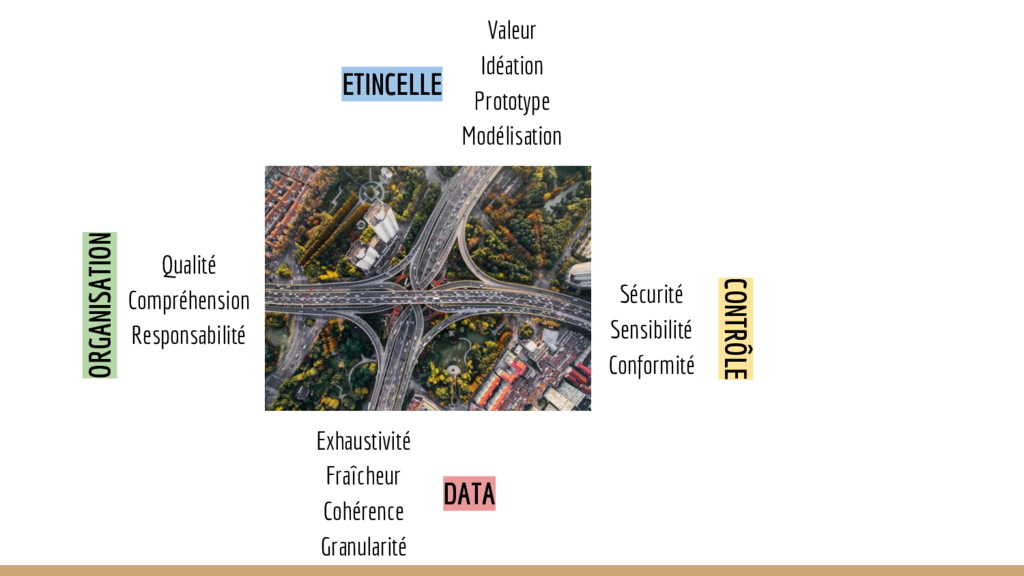
Il y a en gros 4 rubriques dans ce fameux carrefour qu’est notre transformation organisationnelle. Elles correspondent aux 4 grandes entités d’un Data Office, avec 4 grands responsables qui conduisent cette vision.
Nous voyons la problématique de la valorisation de la donnée comme
- un sujet de matière première
- un sujet de gouvernance
- un sujet de contrôle et de sécurisation
- un sujet d’outil et process analytiques
Ce sont les 4 grandes briques de la transformation de l’organisation dont le data office est le porteur.

Sans rentrer dans des discours excessivement théoriques, je trouve que la métaphore du supermarché colle plutôt bien au travail d’un Data Office. Nous avons un staff qui revend des produits et des clients qui viennent et repartent satisfaits. Le service que nous offrons est une prestation autour de la donnée composée de multiples offres selon le client, son besoin et ses exigences.
Les problématiques classiques de la data peuvent ainsi être transposées comme la gestion d’un supermarché.

Sur la partie matière première, le point essentiel à retenir que la donnée n’est pas toujours de nature relationnelle, mais souvent aussi événementielle. L’âge du client est une information liée à son état courant, mais la donnée qui porte le fait de renseigner son âge est également porteuse d’information. Parfois même plus intéressante que l’information principale elle-même :
- Quand a-t-il renseigné son âge ? (ancienneté de la donnée)
- Dans quelles conditions ? (EBanking vs agence vs formulaire papier)
- Quel était son âge précédent ? (à priori mal renseigné)
L’information de type log est la réelle matière première Data, brique de base de notre supermarché. Notons que la diversité des sources de données ouvre la voie à une maximisation de la valeur de la donnée. La richesse provient souvent de cette hétérogénéité. Il vaut mieux avoir plusieurs sources différentes sur une donnée moins riche qu’une seule source très riche. Les algorithmes profiteront alors au maximum de la non-corrélation entre les sources.
C’est donc un supermarché qui doit posséder un maximum de produits, sous tous les formats possible. Conserves, au kilo, petits sachets etc. Sans diversité, le supermarché ne fonctionnera pas.

La fraîcheur est cruciale : cela parait évident mais quand on voit le nombre de feuilles excel qui circulent dans les organisations, sans origine ni “date de péremption”, comment alors oser injecter ce type d’information dans un algorithme ?
Dès qu’elle sort des systèmes opérants, la donnée être captée, stockée, documentée et réinjectée dans un circuit de valorisation aussitôt. Typiquement un circuit analytique (segmentation, scoring, vision 360 etc.).
Notre responsabilité en tant que Data Office est de garantir un niveau de fraîcheur minimal et l’analogie est claire ici : si vous n’avez pas de produits frais qui viennent de sortir de terre, vous pouvez fermer boutique.

La donnée doit être cohérente et cette problématique est souvent absente des mooc ou des challenges data. Il faut être dans une organisation complexe avec une multitude de systèmes opérants ayant chacun un rythme de vie et de mise à jour et qui communiquent dans une forme plat de spaghettis créatif pour le vivre. La data est le vecteur qui unit les systèmes et sans cohérence, difficile de s’y retrouver.
Qu’est ce qu’un client ? Qu’est ce qu’un id client ? Qu’est ce qu’un contrat ? Qu’est ce que “le” numéro de téléphone ? Chaque système vit et a été construit pour un besoin particulier, puis adapté pour communiquer avec les autres systèmes. Chaque système porte la connaissance qui permet de décoder la donnée.
Ce que j’appelle sens de la donnée n’est pas le sens porté par l’interprétation technique en tant que colonne d’une table, mais c’est le sens profond par rapport à cet écosystème applicatif. Les Master Data Management sont censés mettre de l’ordre dans cet écosystème.

La donnée granulaire est à la base du Big Data car elle représente la réalité de la manière la plus fidèle qu’il est possible d’avoir numériquement. Agréger, c’est compresser l’information et donc en perdre. Il faut ainsi veiller à stocker l’état précis de ce qu’il s’est passé, représenté par le log ou la raw data. Ce réflexe de valorisation “raw data” est rarement vu dans les DSIs traditionnelles qui partiront du principe que ce type de donnée a vocation à être archivé en cas de problème ou de contrainte réglementaire.

Du coup quand on récapitule, on a un responsable logistique qui fait le tour des étals et des rayons, vérifie que tout est structuré, bien positionné, en place. Il s’occupe de faire rentrer les gros cartons dans les dépôts, de les déballer puis de les mettre au bon endroit. Il organise la macro-structure du supermarché.
Dans un Data Office, c’est un administrateur fonctionnel de plateformes data.

Dès qu’on rentre dans l’organisation, on sort des considérations techniques. La non qualité de la donnée, on sait tous ce que c’est instinctivement : un numéro de téléphone sans indicatif, une date de naissance renseignée au 1er janvier 1900 ou un champs employeur manquant. Elle peut aussi être plus subtile : une donnée fausse que l’erreur soit voulue ou pas, par exemple le chiffre d’affaire d’une entreprise renseigné en kDH alors que partout ailleurs il est renseigné en DH.
La donnée doit être une image fidèle de la réalité quelque soit sa source ou le traitement qu’elle subit. Pour des raisons techniques, nous sommes obligés de transformer la réalité pour qu’elle tienne dans les systèmes. Par exemple prendre une adresse et l’éclater en lieux/localité/ville/ligne1/ligne2 etc.
Mais garder une image fiable n’est pas un problème technique mais organisationnel. Qui doit définir les règles en amont ? Pour quels types d’usages ? Qui vérifie et recette ? Qui valide ? Comment modifier nos process pour gérer la non qualité sans perdre de morceaux sur le chemin ?
La non qualité inhérente à une mauvaise organisation est une conséquence naturelle des raccourcis techniques et organisationnels pris dans le temps, reflets de trade-offs budget/temps que toute entreprise doit faire pour avancer. Donc une conséquence inhérente à toute organisation suffisamment complexe. La question est comment s’en accommoder ?

Si vous demandez le nombre de clients à 5 entités dans une banque, vous pouvez obtenir 15 réponses différentes selon la compréhension. Client parti, client inactif, client contentieux, client en gel, client résilié …
Il ne s’agit pas de trouver LA définition mais de se mettre d’accord. Il est naturel qu’on ne perçoive pas tous de la même manière le sens de la donnée selon notre métier et/ou nos intérêts.
Un autre exemple est LE numéro de téléphone. On va vouloir lancer une campagne SMS mais au moment de récupérer le moyen de contacter le client, on se rend compte qu’il existe plusieurs types de téléphones. Le téléphone de type CRC est très fiable mais jamais saisi dans le système en tant que téléphone du client. C’est pourtant celui avec lequel le client a appelé récemment. Le téléphone saisi lors de l’entrée en relation date de plusieurs années. Le téléphone utilisé pour l’application mobile paraît un bon compromis, mais qu’en faire si le client ne s’est pas connecté durant les 6 derniers mois. Une simple campagne d’envoi de SMS peut ouvrir des abysses de réflexions sur le sens de “téléphone du client”. Et encore, on ne parle pas de Marocains résidents à l’étranger.

La responsabilité est le pilier principal en terme d’organisation :
- Qui est owner, à qui appartient la donnée si on la pense comme un asset ?
- Qui est responsable ? Le Data Office (qui n’est ni un métier ni informatique), le responsable de la base de donnée, le responsable de la ligne métier dans l’informatique, le responsable métier de l’application qui utilise la donnée, le responsable de l’entité métier dont dépend l’activité portée par la donnée ?
Qui doit s’approprier cet asset ?
Il faut quelqu’un qui considère que le secteur d’activité d’une entreprise est une donnée au coeur de son activité. Une donnée qui mérite toute l’attention, qu’il puisse défendre en terme de requalification ou d’enrichissement avec des bases externes par exemple. La notion de propriété ne doit pas amener de la territorialité mais de la prise de conscience.

Dans un supermarché, c’est le chef de rayon qui met les bonnes étiquettes, dates limite de consommation, prix sur les produits. Il a une vision plus micro que le responsable logistique sur les produits et est chargé de vérifier avec les industriels ce qui est vendu. Le chef de rayon ne porte pas la responsabilité des produits, mais est un relai avec les entités qui les produisent.
Dans un Data Office, c’est le responsable Data Gouvernance.

Le volet contrôle est souvent pris sur un prisme très technique. La sécurité de la donnée rentre traditionnellement dans le cadre de la sécurité des systèmes d’informations, car la donnée est d’abord un actif technique IT. Mais prendre une casquette de sécurité fonctionnelle peut être intéressant pour compléter les aspects non techniques de la protection de l’information :
- Qui accède ? Selon quelle politique ?
- Comment protéger la donnée des collaborateurs (dans une banque c’est une vraie problématique)
- Comment éviter un mauvais usage contraire à des réglementations ou politiques internes ?
- Comment anonymiser correctement la donnée ?

Toutes les informations ne se valent pas d’un point de vue sensibilité. Une fiche de prime n’est pas une annonce de recrutement. Un support de ComEx n’est pas un support de tarification de produit. Il faut bien discerner pour chaque donnée l’impact en terme de risque qu’aurait un usage malveillant ou une diffusion au mauvais public pour la banque.
Il faut donc classifier la donnée selon un certain nombre de critères afin de la gérer et de la protéger de manière optimale. Sans surprotection ni laisser-aller.

Le dernier point concerne la conformité par rapport aux règlements et lois auquel est soumis une organisation. Le plus connu reste le RGPD en terme de protection de la donnée et du client : Tout traitement de donnée doit être accepté et consenti par l’utilisateur qu’il soit analytique (segmentation) ou simplement applicatif (entrée en relation).
Dans une l’ère du Data Is The New Oil, cela parait contraignant pour ne pas dire surréaliste d’avoir de telles régulations mais quand on plonge dedans, on se rend compte qu’elle proviennent d’un bon sens protecteur bienvenu en cette période d’utilisation abusive de la donnée (par exemple en terme de manipulation des opinions sur les réseaux sociaux).

Le responsable sécurité est une forme de super vigile. Il contrôle les tag RFID, les accès des clients. Il peut éventuellement contrôler des clients suspects, leur cabas et les questionner. Son rôle est de sécuriser le fonctionnement du supermarché par rapport aux contraintes et lois en vigueur et se chargera de prévenir la police en cas de problème. Dans un Data Office, il s’agit de la personne dédiée à la protection de la donnée.

Le 4ème et dernier point c’est la fameuse étincelle, l’output final de tout organisation visant à travailler la Data.
Mais avant de parler de datascience, il faut parler de la valeur. Car c’est bien par elle qu’il faut piloter les projets. C’est un vrai shift psychologique tant on peut avoir tendance à être guidés par la dernière forme de hype technologique.
Piloter par le ROI, c’est un réflexe sain d’une organisation data driven. Mesurer au maximum l’outcome de notre travail avec précision. C’est l’assurance d’être financièrement stable et donc de pouvoir réinvestir les bénéfices dans plus de recrutement et plus d’expertise.
Cette approche convient bien dans les startups, plus généralement dans les organisations qui cherchent à survivre. Dans une grosse entreprise plus que centenaire, l’approche n’est pas indispensable mais saine et rationnelle.

L’idéation est un va et vient inlassable entre le monde du rêve et le monde du possible. L’idéation doit cadrer avec douceur et ramener à la réalité ce qui paraît infaisable ou trop ambitieux. Sans castrer ni casser. Eviter les uses case fous tout en laissant la porte ouverte à des ajustements.
Il me semble que c’est un métier difficile car il demande d’avoir un pied dans le métier, dans l’analytics et dans la data pour orienter intelligemment le fonctionnement d’un Data Office. Produire de la valeur est un exercice difficile qui nécessite beaucoup de coordination ainsi qu’un sens du terrain, ce dont nombre d’entre nous manquent, enfermés dans nos laboratoires ou devants nos écrans.

Le prototypage est l’aspect le plus emblématique pour moi de la méthodologie “data”. Prototyper de la donnée, c’est essayer de maîtriser un animal sauvage qui vous regarde dans les yeux et peut aller dans n’importe quelle direction à n’importe quel moment. On ne maîtrise jamais assez la donnée car celle-ci reflète le comportement des gens.
La donnée peut casser un algorithme en autant de temps qu’il a fallu pour construire le modèle. Si la situation change, tout le modèle est cassé car l’algorithme aura sur-appris ou mal-appris sur une réalité qui n’existe plus.
Face à cette problématique, il est nécessaire d’avoir une approche humble et itérative. Toujours garder du recul. Valider ses hypothèses, vérifier les impacts. Ne pas se faire surprendre au moment du passage en production.
La réalité change rapidement, il suffit de voir ce que le Covid-19 a fait de notre société. Il est fort à parier que tout modèle bâti sur la fréquentation agence, le comportement monétique ou les logs de navigation E-Banking sont à refaire d’urgence.

J’ai gardé la créativité pour la fin car c’est the cherry on the cake. Lorsque tous les prérequis sont là, que le business model est validé, que la donnée est bien comprise et de suffisamment bonne qualité, on peut regarder ce qu’on faire.
Dessiner des courbes dans tous les sens, sortir les scatter plot et tenter de modéliser ce qui nous paraît faisable. A ce moment-là, on devrait commencer à voir la magie se matérialiser. Enfin.

L’étincelle est portée par plusieurs personnes dans un supermarché.
- Le responsable marketing, communication et innovation qui est capable de comprendre les clients et penser la data en terme d’offre
- Le chef cuisinier, artiste de la valorisation des produits. Il produira les pâtisseries, rôtisseries et autres valeur ajoutée qui est source importante des revenus d’un grand supermarché
Dans un Data Office, il y a généralement un Responsable Idéation et un Responsable Analytics.

Pour revenir une dernière fois à la métaphore du supermarché, notre travail doit être rigoureux.
Tous les produits sont étiquetés, tout est classifié avec précision, les allergènes correctement labellisés, le poulet rôti est parfaitement cuit. Le client paye un prix pour générer une valeur (calorique) derrière.
Un supermarché ne met pas de tomates en conserve à côté de couches culotte. Ni se permet d’avoir des produits sans prix ou des insectes morts dans le piment vendu au kilo.
C’est ainsi qu’il faut penser son travail : si j’étais dans un supermarché, pourrais-je me permettre d’agir comme ça ? La métaphore du supermarché permet de faire apparaître les mauvais patterns tout en restant fun et didactique.

Voici en résumé les différents rôles dans notre métaphore du supermarché.
