What Will Become of Our Children (in a Post-AGI World)?
Because disagreement is useful, read the best AI-generated counterargument to this article.
No, seriously, what is really going to become of our children in a world where intellectual work seems to be on the verge of becoming almost obsolete?
This is a question I have been asked several times very recently, and it triggered a whole chain of thoughts about the future of white-collar work for young people, and especially very young people (my children are less than one year old).
What could still have value 20 years from now in terms of work? What skills should we start acquiring right now to prepare for that job market? Will there be enough work for everyone, or will we already be living in a world where only a few privileged people (probably scientists) contribute to economic life as producers, and not merely as consumers?
All these questions are hard because they force us to project ourselves forward while trying to extrapolate an exponential curve (the famous exponential growth bias) and, at the same time, predict the moment when that curve falls back down (stagnation of progress, resource scarcity, world wars, some other disruptive event…)
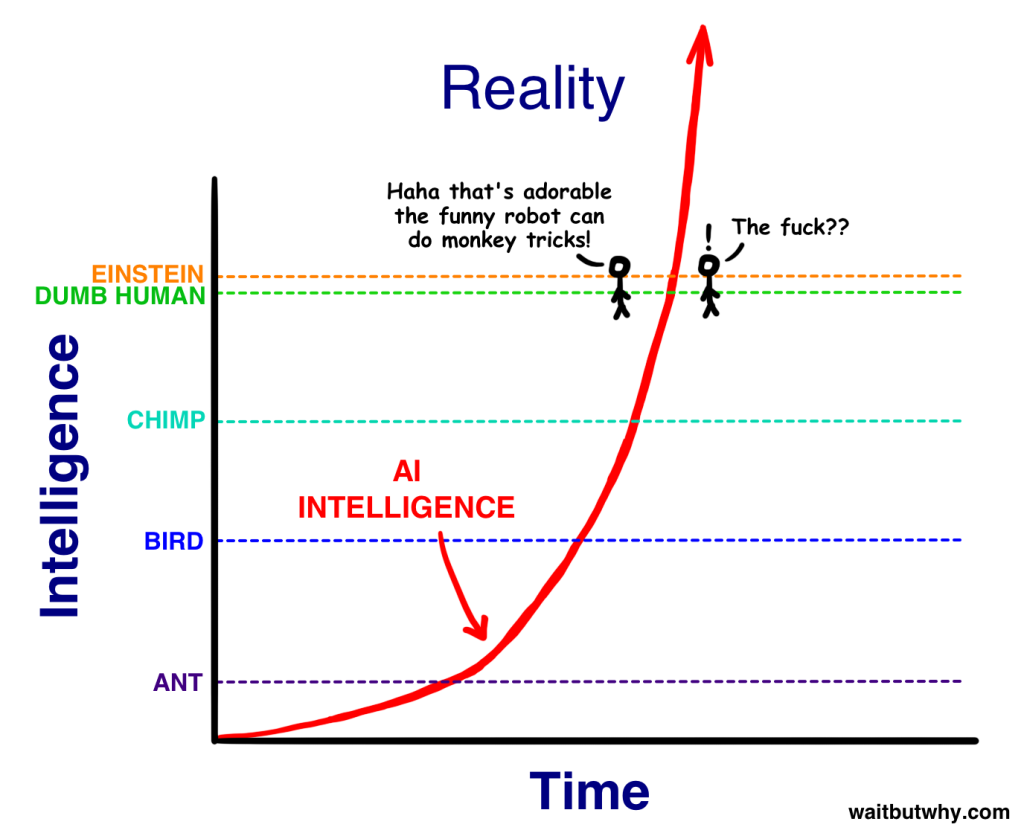
The Race Against Human Intelligence
There is absolutely nothing more fascinating than watching the LLM benchmark race light up across academic and professional circles, as everyone keeps trying to measure with ever more precision the progress of Large Language Models. Fascinating because the benchmarks are becoming more and more complex, and harder for a normal human being to even understand, but also incredibly exciting and terrifying because LLMs keep gaining ground relentlessly on all of them.
The days when social media was celebrating an artificial intelligence capable of passing the American bar exam (GPT4) already feel far away. That was the good old time. Today, generative AI has evolved a lot, and a competition has kicked in where every increment of cognitive capability has become incredibly precious (among other things because it helps raise money).
We now have four major types of benchmarks (at least this is how I see them):
- Generalist benchmarks, which evaluate answers to questions in the style of a student exam: the LLM must not be wrong, must draw from its knowledge, and above all must not hallucinate
- Reasoning-type benchmarks, which evaluate the ability to sustain a line of thought toward a precise objective
- Research-type benchmarks, which require finding information, consolidating it, and answering an extremely precise problem
- Economic benchmarks, which very clearly measure the ability of an LLM to fit into a value chain in the labor market
Let us take one iconic example of each type:
- The GPQA benchmark (448 questions written by expert PhD students in biology, chemistry, and physics, with answers that are not available on Google) is a great example of a complex test where even the best experts do not exceed 60-70% correct answers overall.

On GPQA (and its even harder diamond version), we went from a score of 28% with ChatGPT (GPT-3.5) to 88% with OpenAI o3 (currently leading more or less every benchmark). Since OpenAI o3 is not available to the public, let us note that o3-mini (high), which is available and insanely cheap, reached 80%, still 10 to 20 points above the expert average.
- For anything involving reasoning, it is impossible not to mention FrontierMath, validated by Terence Tao himself, who said it would take several years before it was cracked. FrontierMath is made of 200 extremely advanced mathematical questions, unknown to the general public (and to search engines), impossible to guess randomly, and above all not indexed in the scientific literature. The only way to get to the answer is to do what any good mathematician would do: think, conceptualize, iterate, and move forward.
For the pleasure of the neurons, here is an example of a question where simply understanding the statement deserves a medal.

On FrontierMath, until very recently, even the best models on the market were below 2%. Here again, OpenAI o3-mini and o3 managed to break through the glass ceiling and reach 20-25% on this benchmark (OpenAI being one of the investors in the organization that created the benchmark, one can still ask a few questions).
Another notable reasoning benchmark (algorithmic this time) is Competition Codeforces. In a few words, it is a kind of computer science olympiad with complex algorithmic problems, where tens of thousands of software engineers duel it out for a score and above all a global ranking. The beauty of this benchmark is that it places LLM performance inside an adversarial competitive environment, not only an expert collegial one.

In this benchmark, not only is OpenAI o3 in the top 175 algorithmic coders in the world, but Sam Altman recently stated that an unreleased internal model was ranked 50th worldwide and that they believe they can reach the podium by the end of the year. We can therefore say that AI is a better “computer scientist” than almost all humans, even if we can soften that statement by saying that computer science goes beyond pure algorithmics.
- For research benchmarks, nothing beats HLE (Humanity’s Last Exam), an exam made of 2700 extremely sharp questions whose answers can only be obtained through advanced reasoning abilities and very precise knowledge across the different domains of the test. It is typically what a researcher does: produce deep thinking on a narrow subject by leaning on the iterative work of peers (published research papers), while keeping enough distance from the material.
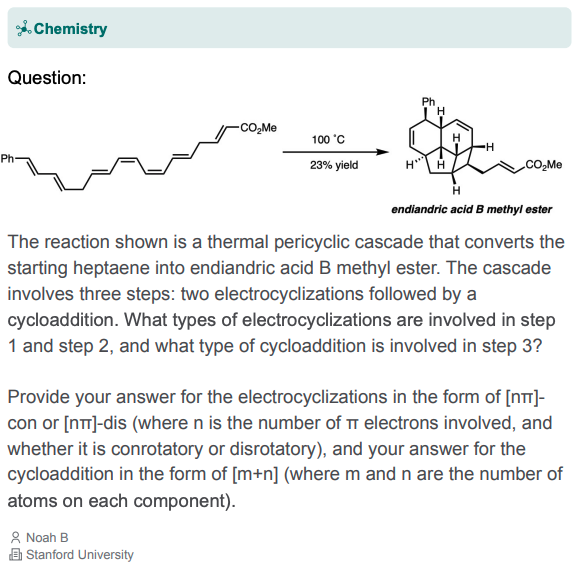
I cannot resist showing two questions here, just to give a sense of the difficulty of this kind of benchmark.

While every LLM before o3 scored under 10% overall, OpenAI o3-mini (high) reached 13%, and OpenAI’s agentic DeepResearch tool based on o3 (the non-public version) is at 27% on this benchmark. Just wow!
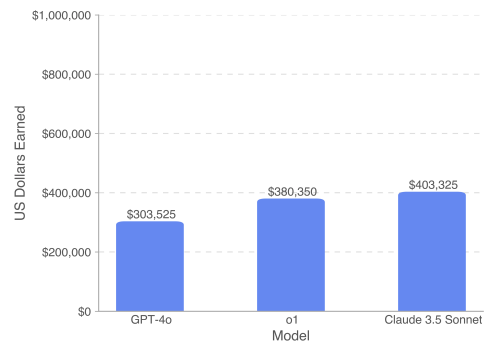
- Finally, my favorite benchmark, the one that simply replaces 50% of my work, is SWE-Lancer — Software Engineer Freelance — a set of real-world software tasks (from the Upwork freelancing platform) whose total market value is 1 million dollars. The goal for the software LLM here is to produce correct answers of good enough quality to be objectively paid by its “client”. LLM performance is then measured by total dollar earnings.
The fundamental objective is to project AI into the economic world and measure practical performance (what better metric than money). A notable fact (and one that will not surprise software engineers who regularly test AI tools): Anthropic, with Sonnet 3.5, not OpenAI, leads this benchmark with $400k earned out of the available million.
Yes, But What Impact on the Real World?
All these theoretical benchmarks obviously do not reflect the reality of the work each of us does every day. The vast majority of us are not paid to solve mathematical puzzles or answer biology questions (even if SWE-Lancer does indeed correspond to a real economic activity).
These benchmarks measure one very particular axis: the ability to crack a subject the way we would at school or university. Our day-to-day work is made of things like: (taking the example of what I used to do when I was Director of the Datalab at CIH Bank)
- Doing technological watch on Big Data and data science
- Reading my emails
- Building and driving a technical and business strategy for data inside the Bank
- Mastering the interpersonal situation inside the bank (hierarchy, relationships, interests)
- Answering my emails in line with the Data strategy and while balancing my understanding of the interpersonal context
- Following and guiding a team through agile rituals (daily and weekly)
- Moving around the offices of managers, sometimes branches
- Developing the Datalake code with the teams
- Reviewing and accepting the Datalake code developed by the team
- Taking a step back on what has been done and adjusting the strategy
- Evaluating the team and my own contribution
In this list of tasks, only a few elements can be handled by LLMs. Development and code review, of course, but also technological watch and the techno-functional data strategy. Although that probably made up 30%-40% of my time as a manager, a non-negligible proportion remains, and this is what I call the “human binding agent”. The ability to draw lines between techno-social systems in order to create value.
More generically, let us note:
- The ability to interact with several information systems through the keyboard, mouse, and screen (reading emails and replying to them, entering a purchasing centralization application, checking an intranet, entering data into an interface, etc.)
- The ability to interact with physical systems (standing in the meeting room with the team at 9:30 in the morning, picking up a Cisco phone handset, walking to a colleague’s office, etc.)
- The ability to maintain a relevant human ecosystem (talking during coffee breaks, going to the cafeteria, exchanging informally in a WhatsApp group, etc.)
Although AI is, in theory, capable of this kind of interaction (and even that is debatable for the human ecosystem), the AI we have today is purely digital and does not naturally interface with the legacy of our real world.
We have tools that are starting to address interaction with computer systems (Browser-use, Anthropic’s Computer Use, HCompany’s Runner, OpenAI Operator), but these remain expensive and generally limited to the web browser, because the web is, by design, highly structured and rather simple to interact with.
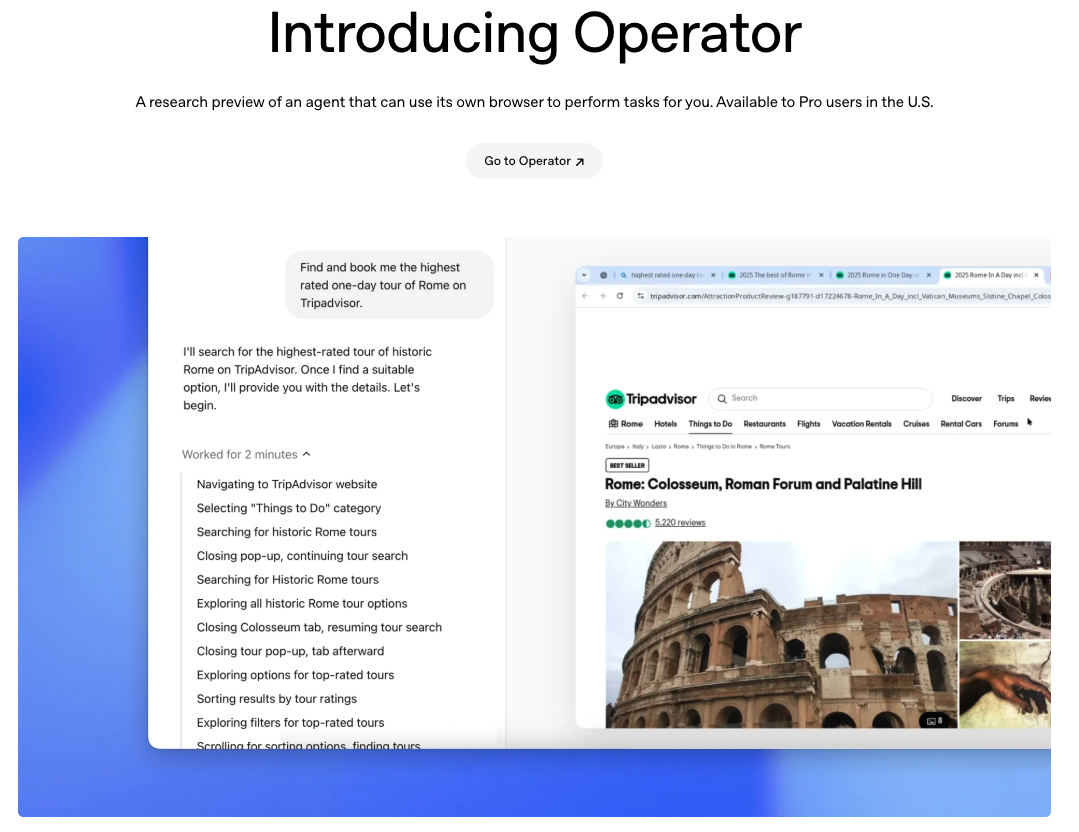
Alongside pure scientific innovation, over the last 6 months we have seen the emergence of the agentic mode of LLMs, meaning their ability to form complex systems to emulate multi-step tasks, emulate teams, and even emulate companies. Agentics is the act of making several agents collaborate together by giving each of them their own assignments, tools, and objectives.
In the following example, a book translation company is reproduced with agents that each have specific characteristics:
- The CEO is an LLM agent that analyzes client needs (specifications) and decides how to assemble the right team for the job (which profiles, how many people for each profile, and the work budget — how long they are allowed to work)
- The senior editor is the LLM agent responsible for giving guidelines to the teams and supervising the work before handing it back to the CEO
- The junior editor is the LLM agent responsible for the operational supervision of the translation teams’ work; it maintains the senior editor’s vision but is expected to work frequently on the deliverables
- The translator is the LLM agent responsible for doing the base work, meaning translating blocks of text while keeping the broader context of the book in mind
- The localization specialist is the LLM agent responsible for adapting the translation to language specificities in particular regions with dialects (in India or China, this is indispensable)
- The proofreader is the LLM agent responsible for proofreading and analyzing grammar, syntax, spelling, etc. in the text
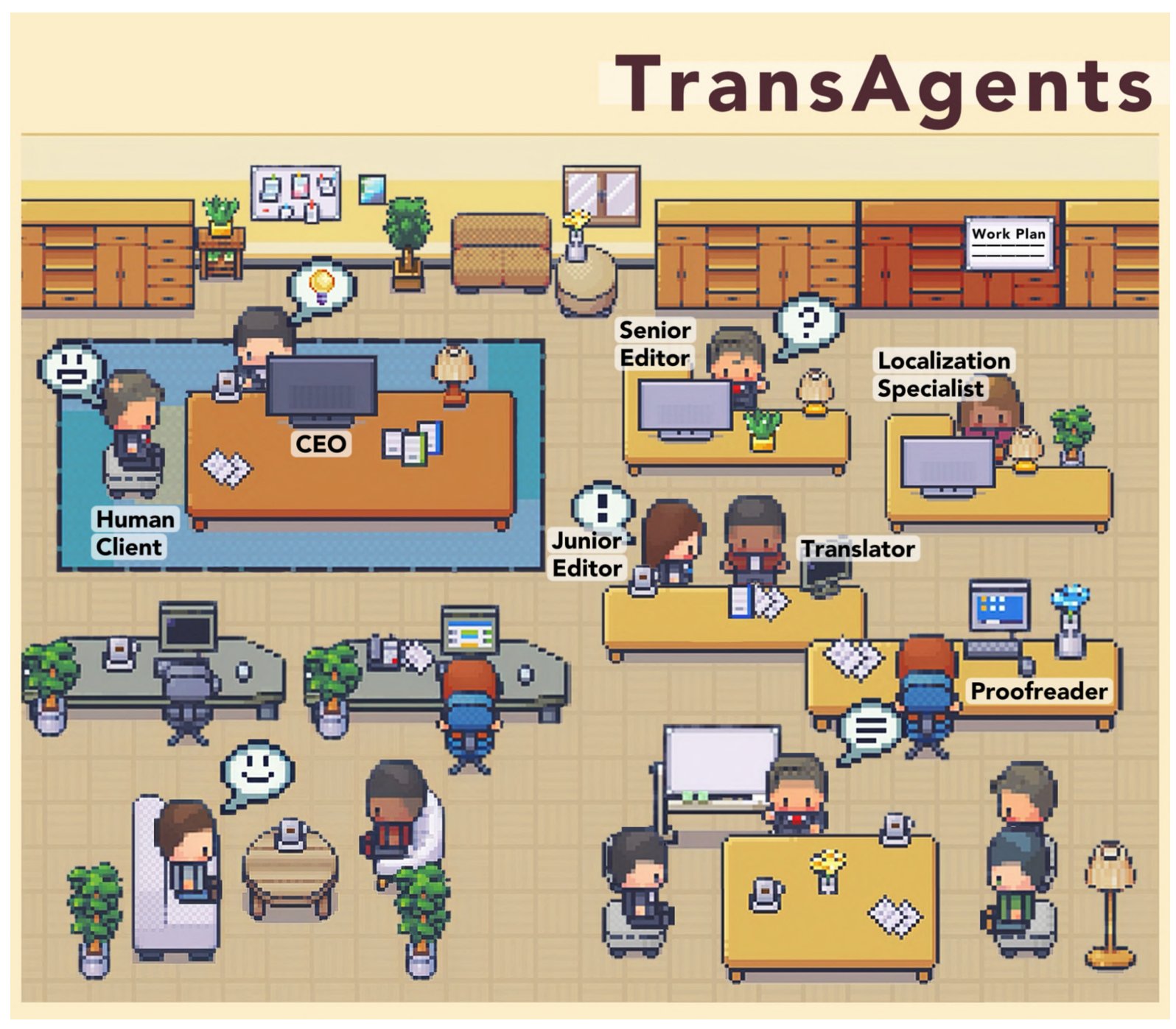
These 6 agents are instantiated one or several times depending on the need and the volume of work. The choice of model (the cognitive power of the LLM) depends on requirements in terms of LLM speed but also the economic equation (a single response from an LLM model can range from $0.01 to $1000 with o3). If needed, they are given access to tools like the web or a dictionary, and they are left to communicate with each other according to a structured workflow that is nevertheless non-deterministic (the proofreader will never talk to the CEO, but the junior editor and senior editor can and must exchange regularly).
We have therefore emulated a book translation company, and the result is supposed to replace human beings on increasingly complex tasks.
Fine, But What About Our Children?
Through their cognitive power, their emerging ability to interact with a computer, and the possibility of teaming up in agentic mode, LLMs are destined to become increasingly generic and invasive.
If they are not capable of replacing us today, I fundamentally see no remaining technical or scientific barrier that prevents them from entering the corporate space and slowly disrupting work. A few important practical parameters will come into play:
- The cost of LLMs must fall in order to become competitive with our salaries (a powerful LLM in agentic team mode using a browser can climb to several hundred dollars per hour)
- The response speed of LLMs is crucial, especially when they are integrated into a human feedback loop (to control and decide before final action). Powerful LLMs remain slow overall; for example, GPT-4.5 only produces around ten tokens per second today
- LLM sovereignty is a sensitive subject because the company selling you its agentic stack is even deeper inside your business than Microsoft Office 365 or Oracle. And we will need Moroccan solutions to answer these challenges
To study the impact on the world of work, a very detailed 2023 World Economic Forum study (already so old and quaint) takes a position on which jobs will disappear.
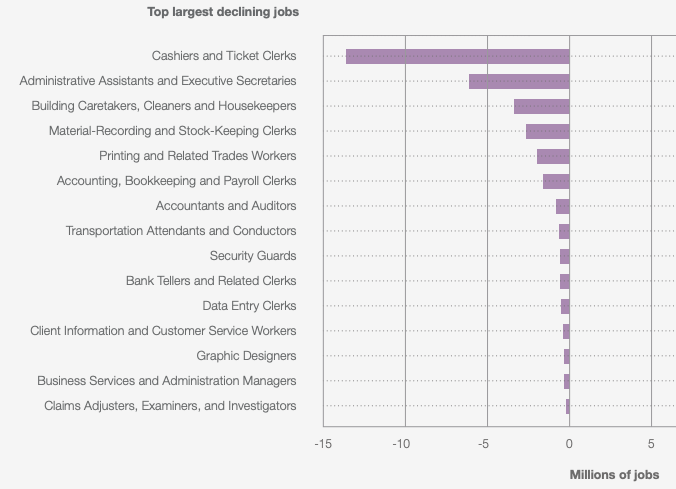
We notably find administrative, accounting, and customer service jobs. Of course, one can criticize this list endlessly, but it is a safe bet that when your work involves little creativity, a lot of digital interaction, and few complex human interactions, agentic LLMs will become a serious competitor.
In computer science, for example, it seems obvious to me that the job market will shrink drastically as agentic AI software tools mature. I estimate that I have the productivity of 4 or 5 people today compared with 10 years ago, when I was returning to Morocco. Those 4 people I did not hire today need to find work somewhere else. As an illustration, note that the number of software engineering job postings in the US is at its lowest point, brushing against Covid levels (the explanation is most likely multifactorial).
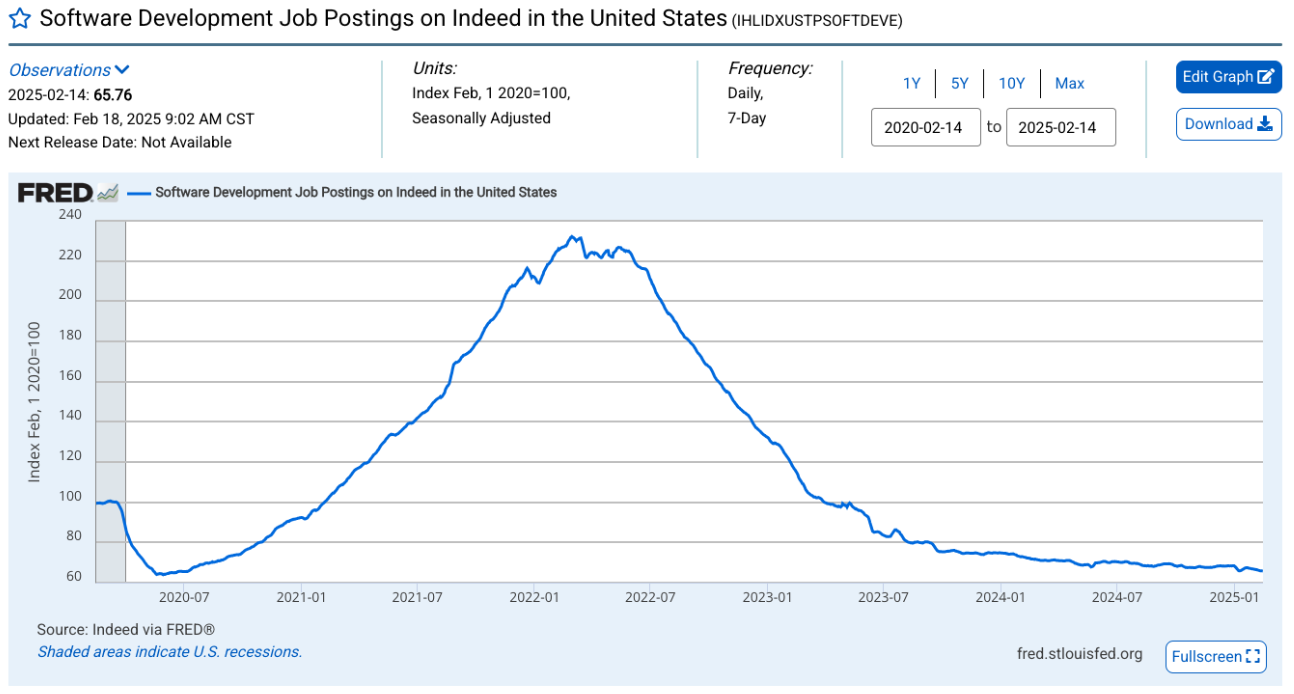
In any case, my children will clearly not be software engineers by profession, but just as nobody gets hired simply because they know how to read and write, the same will be true of algorithmics in the future. An indispensable skill that boosts the elasticity of the brain and engineering capabilities for other jobs still to be invented.
The intermediate stage (5-10 years) will be the rise of increased human-machine collaboration, but it will leave behind a field of ruins for everyone who did not reinvent themselves. It is quite likely that the qualities of the future will center around the strength of human relationships:
- The ability to inspire and preserve trust (corresponding job: opinion leader, politician)
- The ability to show sincere empathy (corresponding job: coach, “friendship”)
- The ability to build a deep and lasting human bond (corresponding job: psychologist, doctor)
As humanoid robots arrive, these last barriers will also fade away.
The Jobs of the Future
I would like to bet on the rise of human sovereignty jobs, those for which society will never be able to accept a machine. I am thinking in particular of politics and administration (deciding our future as a society), justice (in the sense of human judgment between humans), jobs where human contact is an integral part of the work (coaching, family medicine, psychology), and jobs around ethics (which is contained inside human sovereignty).
So what skills will need to be mastered in preparation for this new world (>20 years)? The WEF study answers with a chart that personally speaks to me a lot:
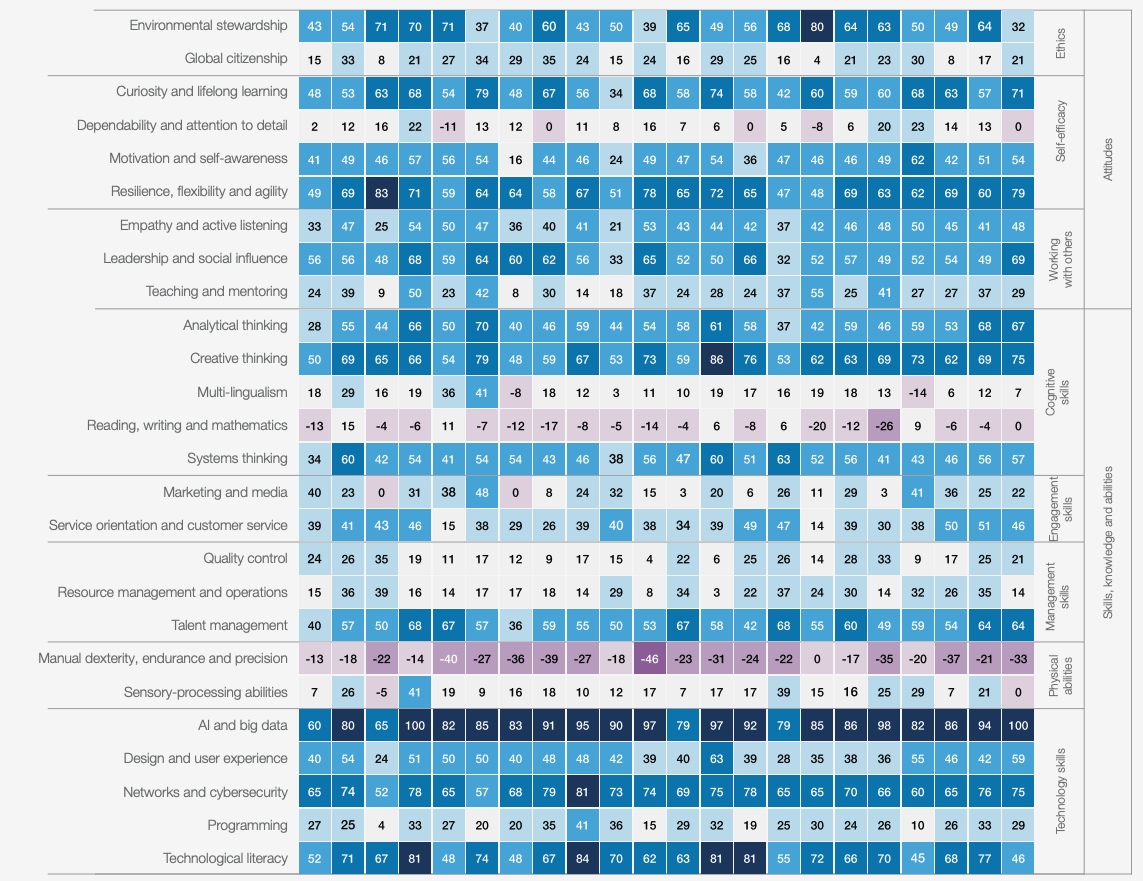
In the future, we will have to teach our children meta-skills:
- Resilience, flexibility, and agility: being able to quickly analyze a situation and adapt to it
- Creative thinking: being able to come up with original solutions thought differently
- Leadership and influence: being able to hold a privileged position in our society
- Curiosity and lifelong learning: being able to have the energy and passion to always want to know more
- AI and Big Data: obviously, we will need to create the robots and artificial intelligences of the future, or at least understand and supervise them, which will still require skills at this level
Our children will be super-entrepreneur startupers, one-person $1B companies as Sam Altman predicted in a conference last year, agile, ambitious, awake minds with a strong and clear will, assisted by thousands of more or less specialized AIs around them, changing the world by drawing the hyphen between machine and human society.
The alternative job to the one that changes the world we live in is the job that changes the future by definition: the researcher, meaning the person who pushes back the limits of what is feasible, while waiting for the inflection point, the beginning of Artificial Super Intelligence. And at that point, we will talk again (or not).
Until then, let us prepare our children for this great revolution!